Qwen3.7 Max Is Now Live on Qubrid AI with Day 0 Access
Today, Qubrid AI is among the first platforms providing Day 0 access to Qwen3.7-Max, Alibaba’s newest flagship model built specifically for the emerging generation of AI agents.
Most frontier model launches today focus on a familiar cycle: larger context windows, slightly stronger benchmark numbers, and incremental reasoning improvements. Qwen3.7-Max feels different because the model is clearly optimized around operational execution rather than conversational polish alone.
That distinction matters more than ever.
The industry is rapidly moving beyond single-turn chat interfaces toward autonomous systems that can write code, coordinate tools, operate inside terminals, navigate repositories, manage workflows, and sustain coherent execution across hundreds or thousands of steps. The challenge is no longer simply generating intelligent responses. The challenge is maintaining reliability once models are embedded inside real production environments.
Qwen3.7-Max appears designed for exactly that problem.
Available Now on Qubrid AI
Qwen3.7-Max is live today on the Qubrid platform with OpenAI-compatible API access.
Access Qwen3.7-Max on Qubrid AI
Teams can integrate the model directly into existing applications, agent frameworks, coding assistants, and orchestration systems without needing to rewrite infrastructure around a custom SDK or proprietary interface.
from openai import OpenAI
client = OpenAI(
base_url="https://platform.qubrid.com/v1",
api_key="QUBRID_API_KEY",
)
response = client.chat.completions.create(
model="Qwen/Qwen3.7-Max",
messages=[
{
"role": "user",
"content": "Summarize this support ticket into bullet-point next steps for the agent."
}
],
max_tokens=500,
temperature=0.7
)
print(response.choices[0].message.content)Operational simplicity matters more than many people realize. Most enterprises already have enough complexity managing inference infrastructure, orchestration layers, vector systems, routing logic, and observability pipelines. Developers increasingly prefer model platforms that reduce migration friction instead of adding another integration surface to maintain.
A Frontier Model Built for the Agent Era
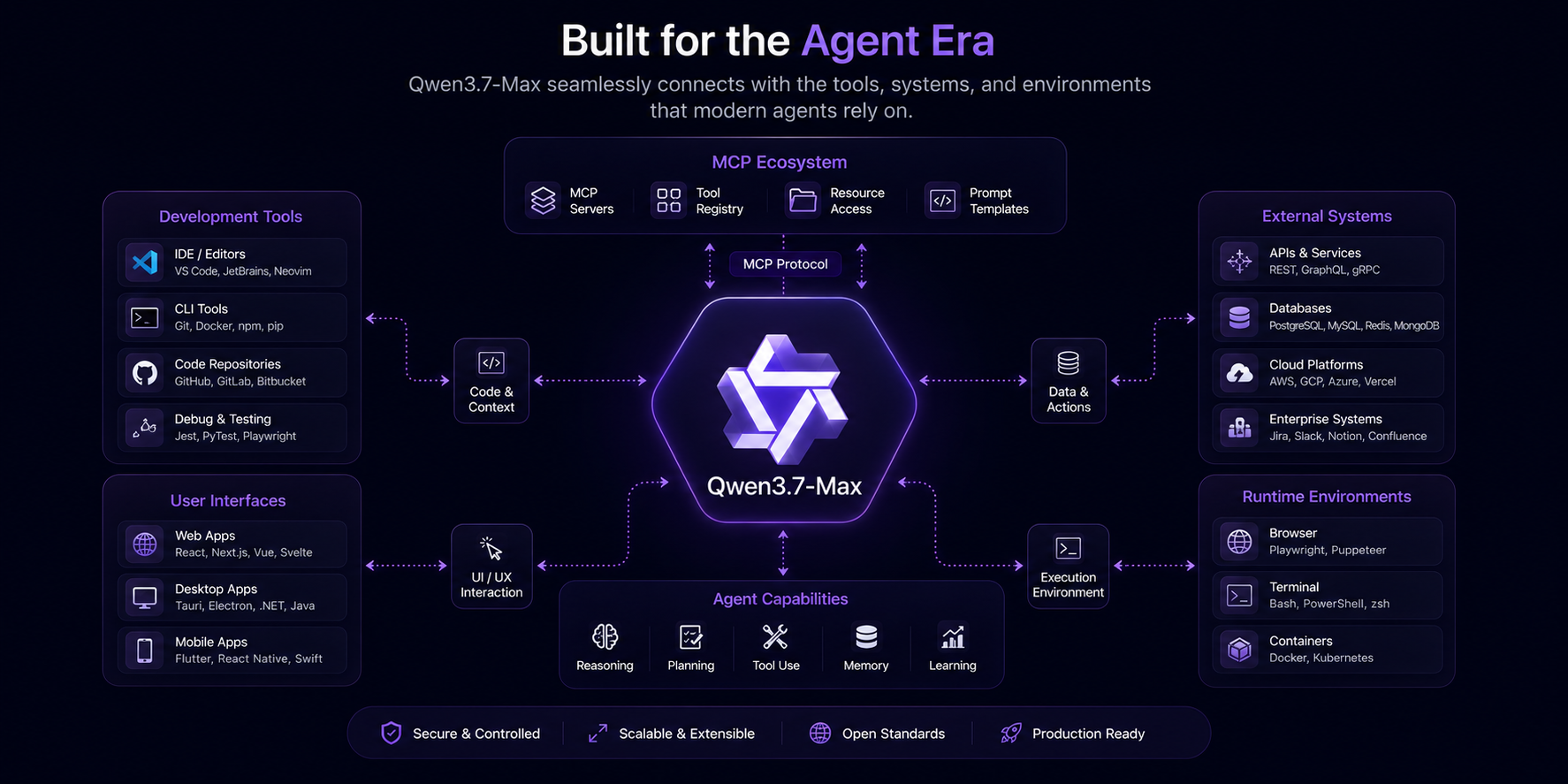
One of the most interesting aspects of the Qwen3.7-Max release is how aggressively the Qwen team focused on “agentic environments” during training.
That shift shows up clearly in the benchmark profile.
Qwen3.7-Max performs strongly across categories that increasingly matter for real-world AI systems:
coding agents
terminal execution
MCP workflows
long-horizon planning
multilingual software engineering
autonomous tool use
workflow orchestration
The model is not optimized for a single narrow scaffold or benchmark harness. According to Qwen, performance remains consistently strong across Claude Code, OpenClaw, Qwen Code, and custom tool-use systems.
That is a much bigger deal than it initially sounds.
A growing number of AI teams are discovering that many models behave well only inside carefully tuned evaluation environments. Once the orchestration stack changes, reliability often drops sharply. Tool calls become inconsistent, execution loops drift, retry behavior becomes unstable, and planning quality degrades over long sessions.
Cross-framework consistency is becoming one of the most valuable traits in production AI systems.
Qwen3.7-Max appears unusually strong in that dimension.
Benchmark Performance That Actually Reflects Real Workflows
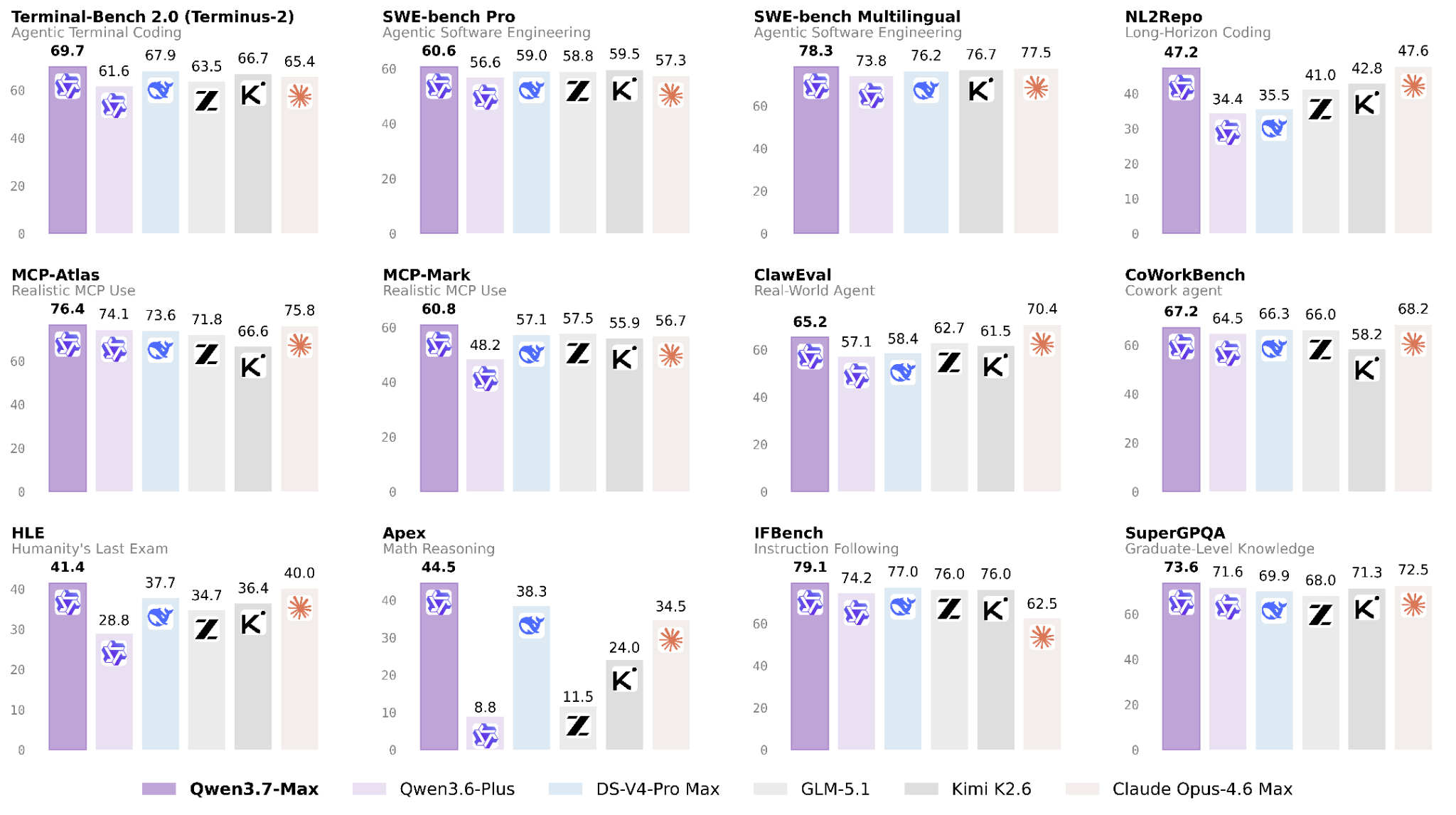
Coding agents, MCP workflows, reasoning, and operational reliability all tell the same story: Qwen3.7-Max is optimized for execution, not just conversation.
Most model benchmark discussions today are difficult to interpret because they compress fundamentally different capabilities into a single narrative around “intelligence.” In practice, modern frontier models fail for very different reasons depending on the environment they operate in.
A model that performs well in static reasoning tests may still struggle with terminal execution. A model that writes impressive single-file code snippets may collapse once repository complexity increases. Another model may perform well in isolated coding tasks but fail once tool orchestration, retry loops, planning drift, and long-horizon execution enter the picture.
That is why the Qwen3.7-Max benchmark profile is unusually interesting.
Instead of dominating only one category, the model performs consistently across coding agents, terminal workflows, multilingual software engineering, MCP-based systems, reasoning-heavy evaluations, and long-horizon operational tasks. The broader pattern across these benchmarks suggests that Qwen3.7-Max is optimized around sustained execution quality rather than benchmark specialization.
The distinction is subtle, but operationally very important.
Terminal Bench 2.0 Shows Strong Real-World Coding Agent Behavior
One of the clearest indicators of practical coding-agent capability is Terminal Bench 2.0, where Qwen3.7-Max scores 69.7, outperforming DeepSeek V4 Pro Max at 67.9 and Claude Opus-4.6 Max at 65.4.
At first glance, the gap may not seem enormous. But Terminal Bench is not a traditional “write a function” benchmark. It evaluates agentic terminal coding behavior under realistic conditions involving repositories, command execution, debugging loops, editing cycles, and sequential task handling.
This matters because modern AI coding workflows increasingly happen inside:
terminal-native environments
agent harnesses
autonomous coding loops
repository-scale execution systems
Developers are no longer just asking models to generate code snippets. They are asking them to:
navigate projects
modify files
execute commands
debug failures
recover from broken states
iterate over multiple execution rounds
Terminal Bench is much closer to that operational reality than older static coding evaluations.
Qwen3.7-Max leading this benchmark strongly suggests the model maintains execution coherence well during iterative workflows, especially when multiple decisions compound over time.
That is one of the hardest problems in autonomous software engineering today.
SWE-Pro and SWE-Multilingual Highlight Production Engineering Strength
On SWE-Pro, Qwen3.7-Max reaches 60.6, outperforming:
Qwen3.6-Plus at 56.6
GLM-5.1 at 58.8
DeepSeek V4 Pro Max at 59.0
Claude Opus-4.6 Max at 57.3
The difference becomes even more notable in SWE-Multilingual, where Qwen3.7-Max reaches 78.3 and establishes a clear lead across the evaluated frontier models.
These benchmarks matter because they move beyond isolated coding tasks and focus more heavily on real software engineering workflows:
repository understanding
multi-file reasoning
debugging
patch generation
long-context software maintenance
structured engineering tasks
The multilingual component is especially important.
A large percentage of production software engineering now happens across multilingual codebases, international developer teams, localized documentation, and globally distributed repositories. Most frontier models still degrade significantly once multilingual complexity enters engineering workflows.
Qwen3.7-Max appears materially stronger there.
That is increasingly relevant for enterprise deployments, global engineering organizations, and AI coding platforms operating beyond English-only environments.
MCP-Mark and MCP-Atlas May Be the Most Important Benchmarks Here
The MCP benchmarks are arguably even more interesting than the coding benchmarks.
Qwen3.7-Max scores:
60.8 on MCP-Mark
76.4 on MCP-Atlas
Those are standout numbers because MCP-style interoperability is rapidly becoming foundational infrastructure for modern AI systems.
The industry is converging around a future where models are not isolated chat interfaces, but operational systems connected to:
browsers
terminals
enterprise tools
databases
APIs
productivity systems
internal workflows
MCP environments evaluate whether a model can reliably coordinate those systems while maintaining structured execution behavior.
This is where many frontier models begin to break down.
Tool use becomes inconsistent. Execution order drifts. Context windows become noisy. Retry loops spiral. Agents lose track of system state. Planning quality collapses over longer interactions.
Qwen3.7-Max performing strongly in MCP environments suggests the model has unusually good operational discipline under structured workflows.
That is a very different capability from simply generating intelligent-looking text.
And it is arguably more valuable for production AI systems.
ClawEval and CoWorkBench Reveal a Bigger Shift in AI Agents
The ClawEval and CoWorkBench scores are also revealing.
Qwen3.7-Max scores:
65.2 on ClawEval
67.2 on CoWorkBench
These benchmarks evaluate more realistic agent behavior involving long-horizon productivity workflows and collaborative execution environments.
This category matters because the next generation of AI systems will likely look less like “question-answer bots” and more like operational coworkers:
coding copilots
workflow agents
research assistants
productivity orchestrators
enterprise execution systems
The challenge in these environments is not merely intelligence. It is consistency over time.
Maintaining coherent strategy across long execution chains remains one of the largest unsolved problems in agentic AI. Most models today eventually degrade under extended operational load:
context drift increases
hallucinations compound
planning loops become unstable
retries become repetitive
execution quality regresses
Qwen3.7-Max appears significantly more resilient under those conditions.
That operational resilience may ultimately matter more than isolated benchmark peaks.
HLE, Apex, and SuperGPQA Show Frontier-Level Reasoning
The reasoning benchmarks reinforce the same pattern.
Qwen3.7-Max achieves:
41.4 on HLE
44.5 on Apex
73.6 on SuperGPQA
The Apex score is particularly notable because it significantly outperforms:
GLM-5.1 at 11.5
Kimi K2.6 at 24.0
Opus-4.6 Max at 34.5
DeepSeek V4 Pro Max at 38.3
These are difficult reasoning environments designed to evaluate deeper cognitive consistency rather than superficial pattern matching.
What stands out is not simply that Qwen3.7-Max performs well. It is that the reasoning strength appears to carry over into operational agent benchmarks rather than existing in isolation.
That crossover is important.
Many models today perform strongly in academic reasoning tasks but degrade once real execution systems are introduced. Qwen3.7-Max appears much better at translating reasoning capability into actionable operational behavior.
That combination is rare.
The Bigger Story Is Cross-Benchmark Consistency
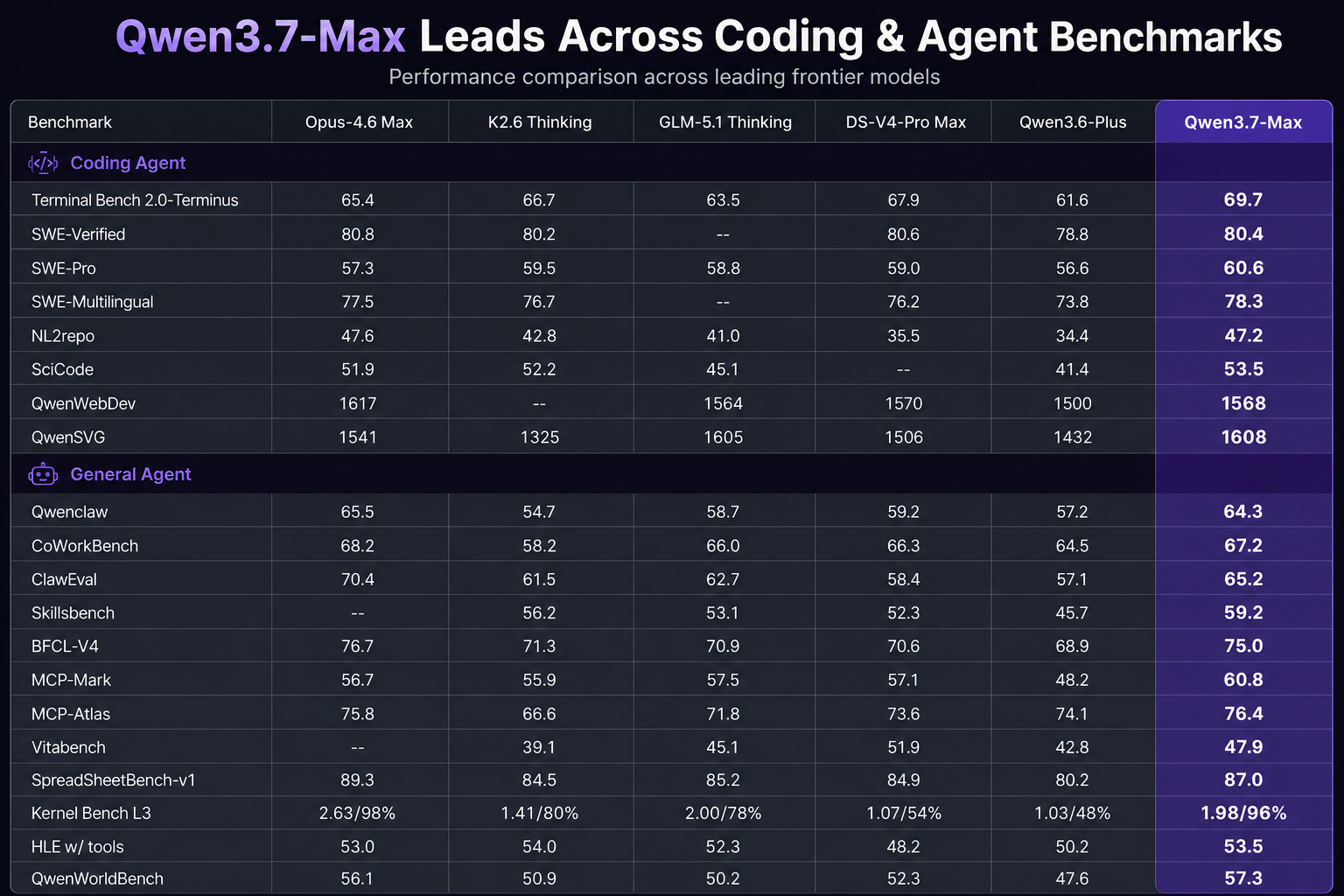
The most important takeaway from this benchmark suite is not any single score.
It is the consistency across fundamentally different environments:
coding agents
MCP systems
multilingual engineering
reasoning benchmarks
cowork agents
long-horizon execution
productivity workflows
Most frontier models today still exhibit sharp specialization patterns. They dominate certain benchmark categories while remaining operationally fragile elsewhere.
Qwen3.7-Max looks more balanced.
That balance matters enormously for production AI infrastructure because real-world systems rarely operate in isolated benchmark conditions. Production agents continuously move between:
reasoning
tool use
retrieval
execution
planning
debugging
structured workflows
dynamic environments
Models optimized only for isolated conversational intelligence often become unreliable once those systems interact continuously over time.
Qwen3.7-Max appears much more operationally stable across those transitions.
And increasingly, that is what developers actually need.
The Long-Horizon Execution Story Is What Really Stands Out
The most fascinating section of the Qwen release may not be the benchmark table at all.

Qwen describes a 35-hour autonomous kernel optimization task where Qwen3.7-Max continuously operated across more than 1,100 tool calls and 432 kernel evaluations, ultimately achieving a 10x geometric mean speedup over the original implementation.
What makes this interesting is not merely the final score.
The model reportedly maintained coherent optimization strategy over extremely long execution horizons while:
debugging compilation failures
redesigning kernel architecture
profiling runtime bottlenecks
iterating on optimization strategies
recovering from errors autonomously
That kind of sustained execution remains one of the hardest unsolved challenges in agentic AI.
Most models today still degrade significantly during extended workflows. Context begins drifting, planning loops collapse, retries become repetitive, and the system gradually loses strategic coherence. Qwen3.7-Max appears materially stronger at maintaining productive momentum over long operational sessions.
That capability becomes increasingly important as AI systems move toward autonomous software engineering, infrastructure optimization, research agents, and multi-hour workflow execution.
Why This Matters for Production AI Teams
The benchmark numbers are impressive, but the operational implications matter more.
Most teams today are no longer blocked by model access. They are blocked by reliability:
unstable tool usage
inconsistent execution
brittle orchestration behavior
weak long-context coherence
framework-specific failures
unpredictable agent planning
Developers care less about theoretical context length and more about whether a model remains dependable after hundreds of sequential decisions inside a production workflow.
That is where Qwen3.7-Max appears especially compelling.
For teams building coding copilots, autonomous engineering agents, multilingual enterprise assistants, browser automation systems, or MCP-driven workflows, the model offers a strong balance of reasoning depth, tool-use consistency, and operational stability.
Frontend Generation, Office Automation, and Beyond
Qwen also showcased several practical deployment scenarios that align closely with where the broader AI ecosystem is heading.
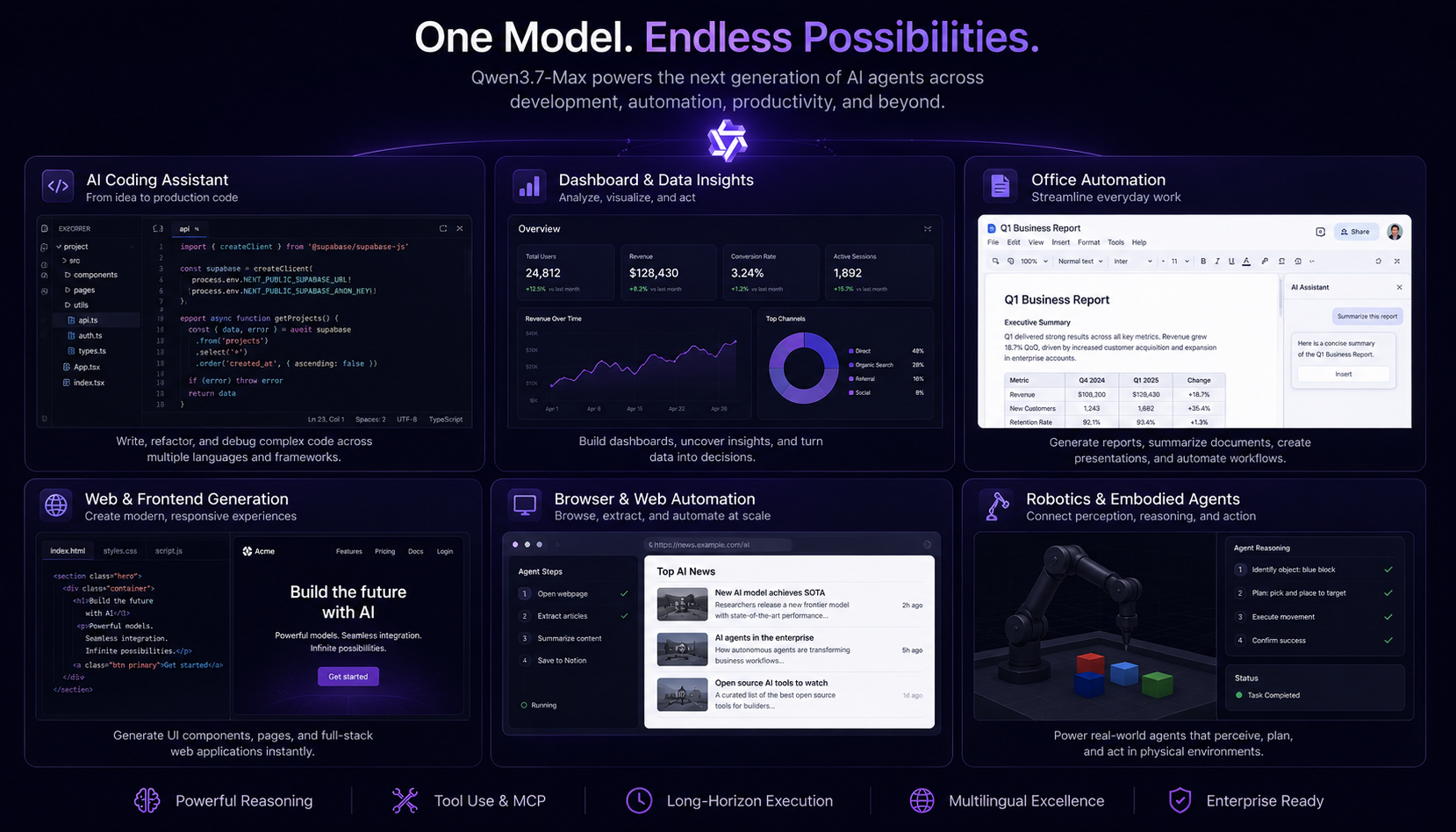
The model demonstrates strong frontend generation capabilities, including dynamic web interfaces, SVG-heavy rendering, Three.js environments, and interactive UI generation from single prompts. On the productivity side, Qwen3.7-Max also performs strongly in office automation workflows through MCP integrations and autonomous tool execution.
These use cases matter because the market is shifting away from isolated chat experiences toward systems that can directly operate productivity environments, developer tooling, and enterprise workflows.
The future of AI infrastructure increasingly looks less like “ask a chatbot a question” and more like “delegate execution to an operational agent.”
Qwen3.7-Max feels built for that transition.
Available Now on Qubrid AI
Qwen3.7-Max is now live on Qubrid AI Platform with Day 0 availability.
As the AI ecosystem moves toward:
agent-native architectures
scalable inference infrastructure
tool-oriented execution systems
autonomous coding workflows
long-running operational agents
…models optimized for execution reliability will increasingly become foundational infrastructure layers rather than experimental research demos.
At Qubrid AI, we believe the next generation of AI systems will be defined not just by intelligence, but by operational consistency under real workloads.
Qwen3.7-Max is one of the strongest examples of that shift so far.


