The Ultimate Guide to NVIDIA Nemotron 3 Nano 30B-A3B: Build Fast, Long-Context AI Applications with Qubrid’s Free Inference Playground
High-performance LLM inference powered by NVIDIA Nemotron 3 Nano, running on Qubrid AI.
Master long-context reasoning, coding, and agent workflows using NVIDIA’s most efficient open LLM. A practical guide by the Qubrid AI team for developers and startups.
The landscape of open-source large language models has changed again.
With the release of NVIDIA Nemotron 3 Nano 30B-A3B, developers finally get what they’ve been asking for:
Massive context (up to 1M tokens)
Strong reasoning and coding performance
Fully open weights
Much faster inference than traditional 30B models
And the best part?
You can try it instantly on Qubrid AI - no GPU setup, no infrastructure headaches, and free tokens to get started.
Why NVIDIA Nemotron 3 Nano 30B-A3B?
Nemotron 3 Nano is not just another 30B model.
It’s built using a hybrid Mixture-of-Experts (MoE) + Mamba-2 architecture, which means:
Only a small portion of the model is active per token
Significantly higher throughput
Much lower inference cost for real-world applications
Key Highlights for Developers
Extremely fast inference - Activates ~3.5B parameters per token instead of all 30B
Ultra-long context - Supports up to 1,000,000 tokens, ideal for RAG, agents, and document intelligence
Strong reasoning & coding - Trained with reinforcement learning for multi-step reasoning
Fully open weights - Safe for startups and commercial usage
Agent-ready - Designed for tool use, planning, and multi-turn workflows
If you’re building AI agents, copilots, developer tools, or internal assistants, Nemotron 3 Nano is a serious upgrade.
Nemotron 3 Nano vs Qwen3 30B-A3B
A common question we get is: “How does this compare to Qwen3 30B-A3B?”
Here’s a clear, developer-focused comparison:
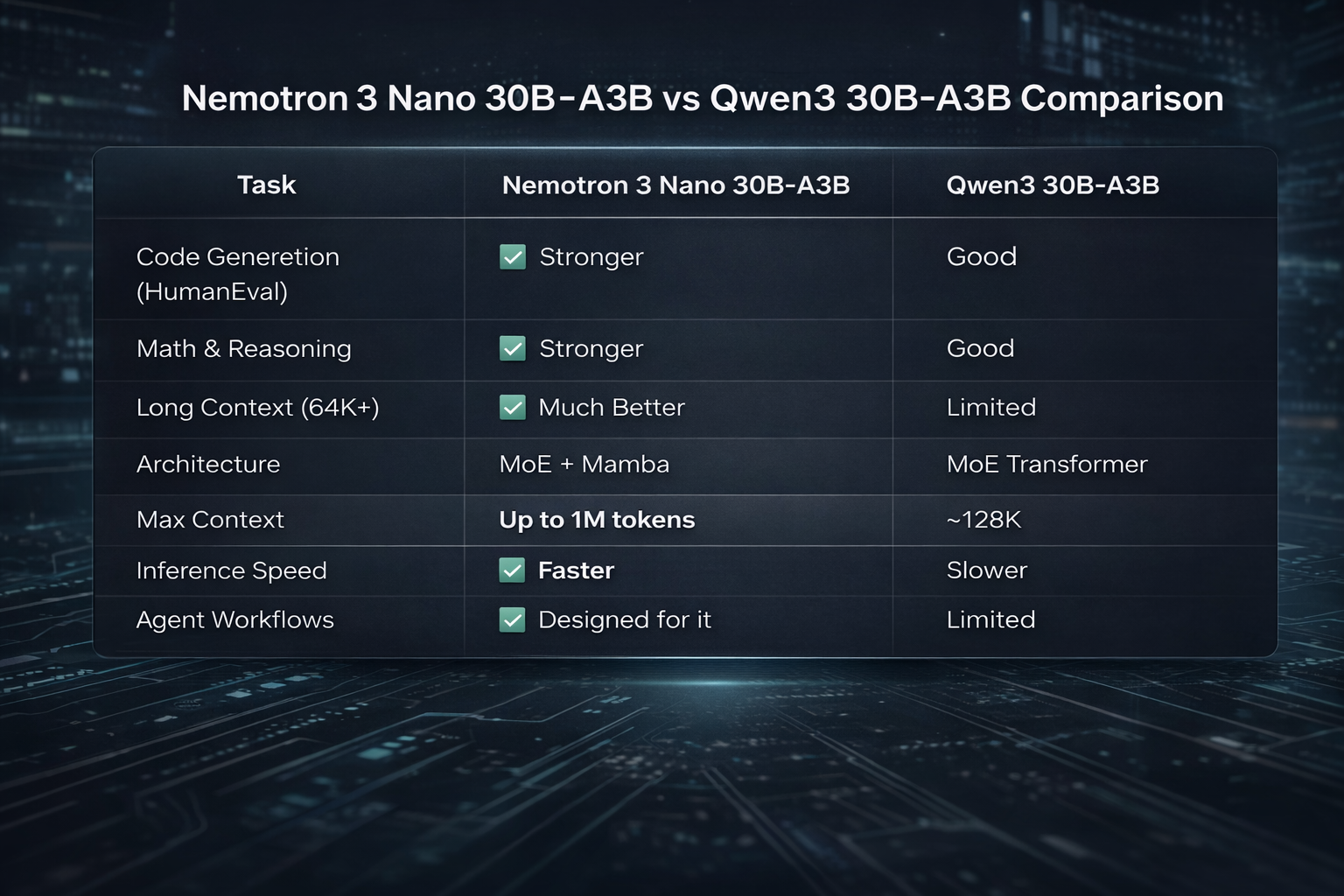
👉 Summary: If your workload involves long documents, reasoning, coding, or agents, Nemotron 3 Nano clearly wins.
Step 1: Get Started on Qubrid AI (Free Tokens)
Qubrid AI is built for developers who want:
Fast inference
Lowest pricing
Zero infrastructure management
Getting started is simple:
Sign up on the Qubrid AI platform
Receive free credits (enough to run real workloads)
Access Nemotron 3 Nano instantly from Model Studio
No GPUs. No Docker. No setup.
Step 2: Try Nemotron 3 Nano in the Playground
Before writing any code, test the model live.
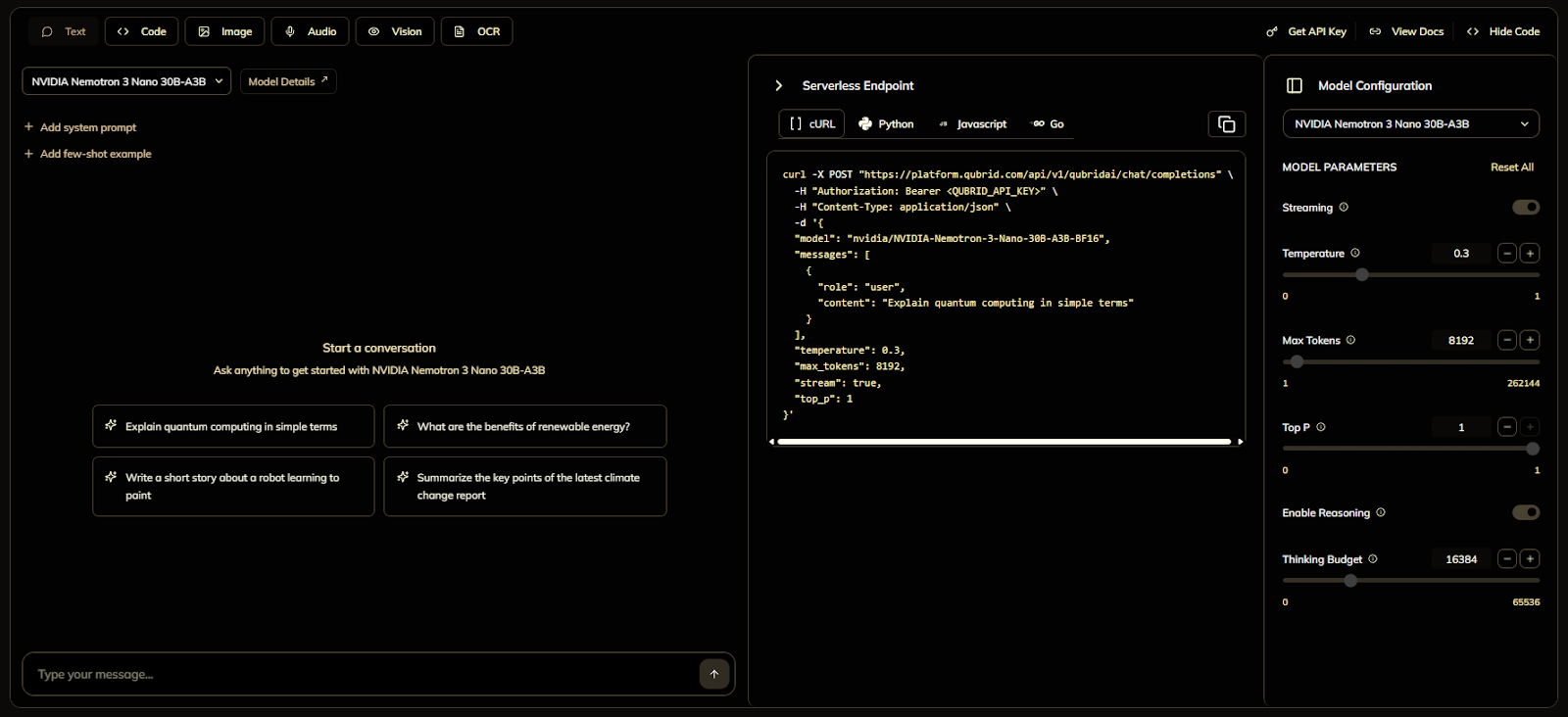
How to Test
Open Model Studio
Select NVIDIA Nemotron 3 Nano 30B-A3B
Enter a prompt like:
"Explain how Mixture-of-Experts models improve inference efficiency, with examples."
Or explore examples: https://github.com/QubridAI-Inc/open-llm-examples/tree/main/Models/nemotron-3-nano
You’ll immediately notice:
Clear reasoning
Structured output
Strong technical explanations
💡 Ideal for prompt testing, RAG validation, and stakeholder demos.
Step 3: Generate Your Qubrid API Key
To integrate Nemotron into your application:
Log in to Qubrid
Open API Keys from the dashboard
Create and securely store your key
You’re now ready to build.
Step 4: Integrate Nemotron 3 Nano via Python API
Below is a standard Qubrid AI inference pattern for text generation:
import requests
import json
url = "https://platform.qubrid.com/api/v1/qubridai/chat/completions"
headers = {
"Authorization": "Bearer <QUBRID_API_KEY>",
"Content-Type": "application/json"
}
data = {
"model": "nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16",
"messages": [
{
"role": "user",
"content": "Explain quantum computing in simple terms"
}
],
"temperature": 0.3,
"max_tokens": 8192,
"stream": true,
"top_p": 1
}
response = requests.post(url, headers=headers, data=json.dumps(data))
for line in response.iter_lines():
if line:
decoded = line.decode("utf-8")
if decoded.startswith("data: "):
payload = decoded[6:]
if payload.strip() == "[DONE]":
break
chunk = json.loads(payload)
print(chunk["choices"][0]["delta"].get("content", ""), end="")
The response is high-quality, structured, and production-ready.
What Can You Build with Nemotron on Qubrid?
Teams are already using it for:
Long-context RAG (legal, research, enterprise knowledge bases)
AI agents (tool calling, planning, multi-step automation)
Developer tools (code review assistants, internal copilots)
Startup products (chatbots with memory, analytics copilots)
All without managing GPUs.
Why Developers Choose Qubrid AI
Lowest inference pricing
Fastest open-model serving
Developer-first APIs & Playground
No GPU or infrastructure setup
Free credits to start
If you want to run NVIDIA Nemotron 3 Nano 30B-A3B in production, Qubrid AI is the easiest and fastest way.
Start Building Today
👉 Try NVIDIA Nemotron 3 Nano 30B-A3B on Qubrid AI Playground: https://qubrid.com/models/nvidia-nemotron-3-nano-30b-a3b


