Local AI vs Cloud AI: What’s Actually Happening in 2026?
For the last two years, most of the AI industry has operated under a simple assumption: the future of artificial intelligence would belong almost entirely to massive cloud models running inside hyperscale datacenters.
At first, that assumption looked completely correct.
The most capable models required enormous GPU clusters, advanced networking, billions of dollars in infrastructure, and highly specialized inference stacks. Running serious AI workloads locally was mostly limited to hobbyists, researchers, and a small number of infrastructure-heavy organizations.
But something changed faster than almost anyone expected.
The models improved.
The hardware improved.
The inference stacks improved.
And most importantly, people began realizing that not every AI workload actually requires frontier-scale reasoning.
That realization is now reshaping how modern AI systems are being designed.
The industry is slowly moving away from the question of: “Which single model is the best?” toward a much more important question: “What is the smartest architecture for the workload?”
And increasingly, the answer is neither fully local nor fully cloud. The future appears to be hybrid.
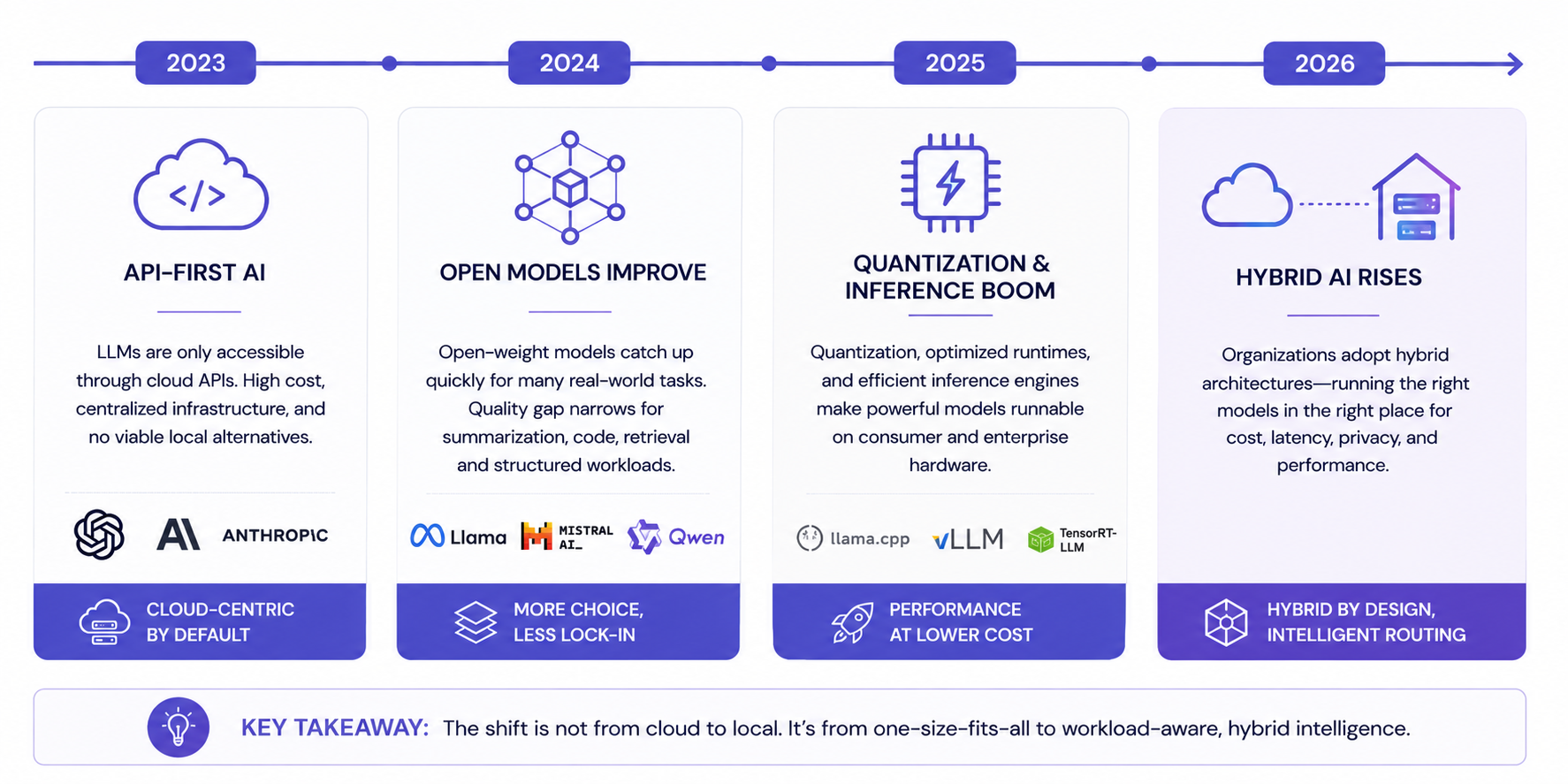
The Original Cloud Assumption
When ChatGPT launched, cloud AI became the default architecture almost overnight. It made perfect sense. Large language models were incredibly expensive to run, required large amounts of VRAM, and depended heavily on datacenter-grade infrastructure.
For most developers and companies, APIs solved everything.
Instead of worrying about GPUs, inference optimization, networking, scaling, uptime, or memory management, organizations could simply send prompts to a hosted endpoint and receive intelligent responses in return.
That abstraction accelerated AI adoption dramatically.
But the cloud-first assumption also created a belief that local AI would remain permanently behind - both technically and economically.
That assumption now looks increasingly incomplete.
Why Local Models Improved Faster Than Expected
The biggest surprise in AI over the past 18 months has not necessarily been frontier model progress.
It has been how usable smaller and open-weight models became in practical production workflows.
A huge percentage of enterprise AI usage today is not solving PhD-level reasoning problems. Most real-world workflows revolve around structured tasks:
Code explanation
Summarization
Document retrieval
Formatting
Classification
Internal copilots
Agent workflows
Boilerplate generation
Data extraction
Search augmentation
For these tasks, many open and local models became “good enough” far earlier than expected.
This happened because several independent trends accelerated simultaneously.
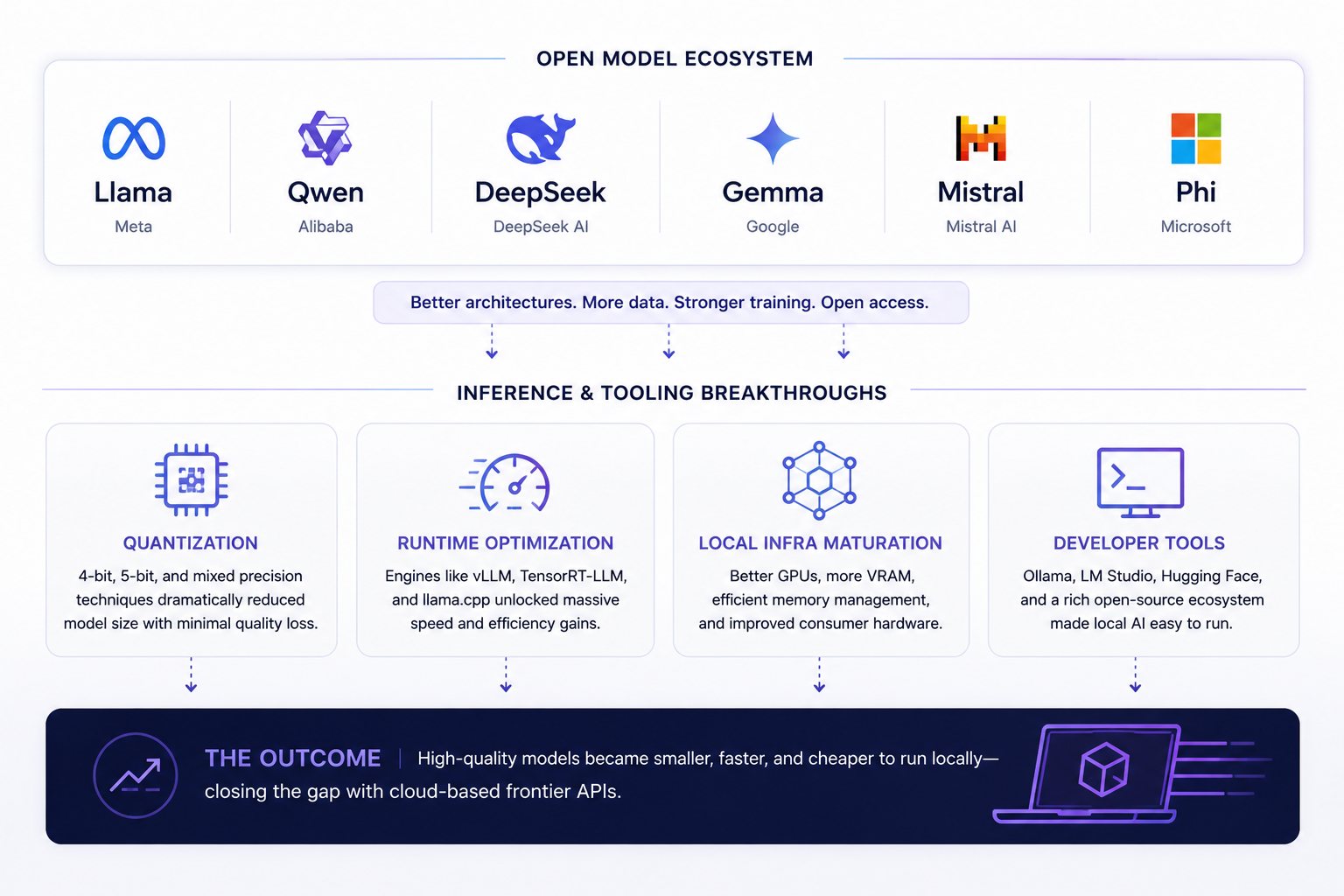
Open-weight models improved rapidly. Qwen, Llama, Gemma, Mistral, DeepSeek, and other ecosystems dramatically reduced the quality gap for common workloads. Quantization techniques improved enough that large models could run surprisingly well on smaller hardware footprints. Inference engines such as vLLM, llama.cpp, TensorRT-LLM, and Ollama made deployment significantly easier and more efficient.
At the same time, the industry improved almost every layer of inference optimization:
Paged attention
Continuous batching
KV cache optimization
Speculative decoding
Memory offloading
Tensor parallelism
Individually, each improvement mattered. Combined together, they changed the economics entirely.
The result is that many organizations are now discovering they do not need frontier cloud reasoning for every single inference request.
The Economics Are Changing Faster Than The Benchmarks
One of the most misunderstood parts of the local-vs-cloud discussion is that benchmark leadership is not always the primary business metric.
Economics often matter more.
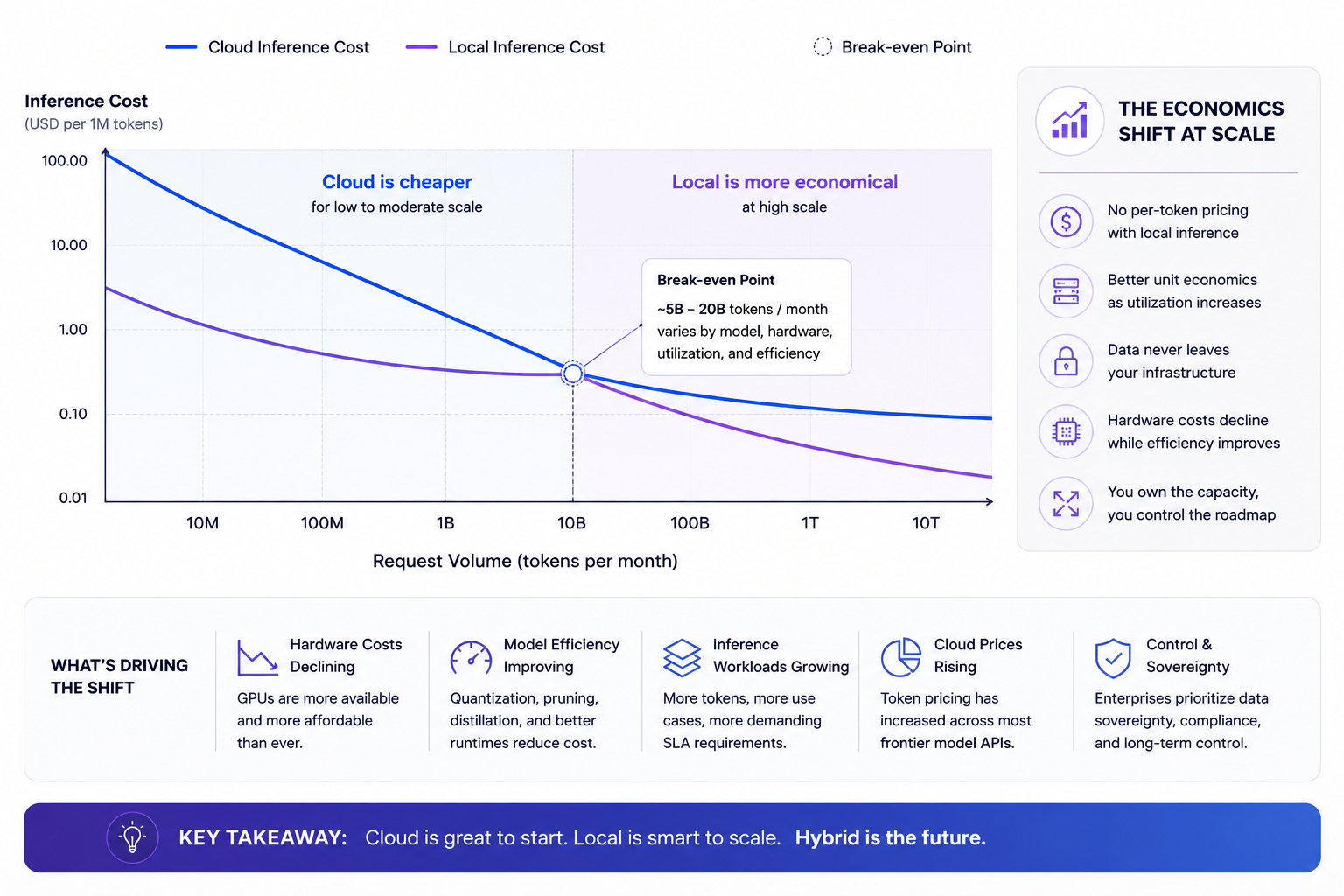
A frontier cloud model may absolutely outperform a local model in raw capability. But if a workload only requires “sufficient intelligence,” then cost, latency, privacy, and operational predictability become far more important.
This is especially true at scale.
A company processing millions of repetitive inference requests eventually begins optimizing differently from an individual experimenting with AI products.
At low scale, APIs are extraordinarily efficient.
At large scale, inference costs become infrastructure decisions.
This is where local AI becomes increasingly attractive.
Once hardware is deployed, local inference can dramatically reduce marginal costs for repetitive workloads. Organizations running internal copilots, document systems, retrieval-heavy pipelines, or batch inference workflows often discover that local models provide enough capability while significantly improving cost predictability.
The shift is subtle but important.
The industry is no longer only chasing maximum intelligence.
It is increasingly optimizing for intelligence-per-dollar.
Why Cloud AI Still Dominates Frontier Workloads
Despite the excitement around local AI, cloud models continue to dominate the absolute frontier - and likely will for quite some time.
There are several reasons for this.
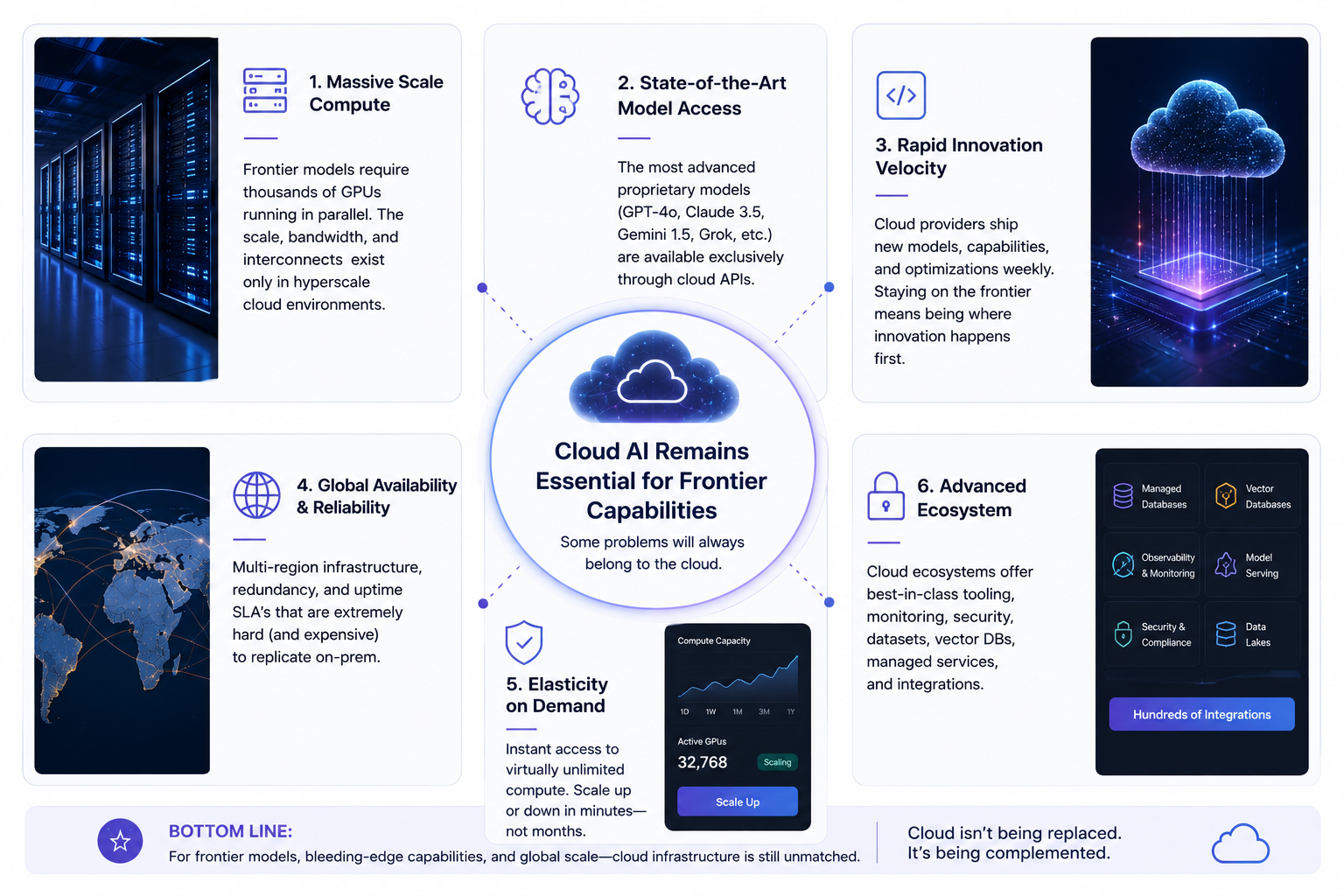
The largest reasoning models still require enormous distributed infrastructure. Frontier-scale inference depends heavily on massive GPU clusters, advanced networking, and highly optimized serving architectures that remain inaccessible to most organizations.
Cloud providers also maintain significant advantages in:
Long-context reasoning
Large-scale agent orchestration
Massive concurrency
Multi-modal processing
Real-time distributed scaling
Continuous model updates
Most importantly, cloud infrastructure dramatically simplifies operations.
For many companies, paying for an API remains easier than managing GPUs, drivers, inference optimization, uptime, observability, autoscaling, and hardware procurement.
And while local AI is improving rapidly, training frontier models remains fundamentally centralized due to capital expenditure requirements and infrastructure complexity.
Cloud AI is not disappearing.
In fact, overall cloud AI demand is still growing aggressively.
The difference is that organizations are becoming more selective about which workloads actually require frontier cloud reasoning.
The Rise of Hybrid AI Architectures
This may ultimately become the defining infrastructure trend of modern AI.
The future is probably not “all local.”
And it is probably not “all cloud.”
The future is intelligent workload routing.
Modern AI systems are increasingly being designed around layered architectures where different models handle different types of tasks.
A lightweight local model may handle summarization or classification. A larger open-weight model may process coding or retrieval-heavy tasks. Only highly complex reasoning requests may escalate to expensive frontier cloud models.
This architecture changes everything economically.
Most AI workloads are not uniformly difficult.
In many real-world systems, a small percentage of prompts consume a disproportionate amount of reasoning resources.
That means companies can optimize aggressively through routing.
Instead of paying frontier-model pricing for every request, organizations can selectively allocate expensive reasoning only where it creates meaningful value.
This is already beginning to happen across enterprise AI infrastructure.
Latency, Privacy, and Sovereignty Are Becoming Strategic Advantages
One reason local AI is accelerating so quickly is because the conversation has expanded beyond model quality alone.
Operational characteristics now matter enormously.
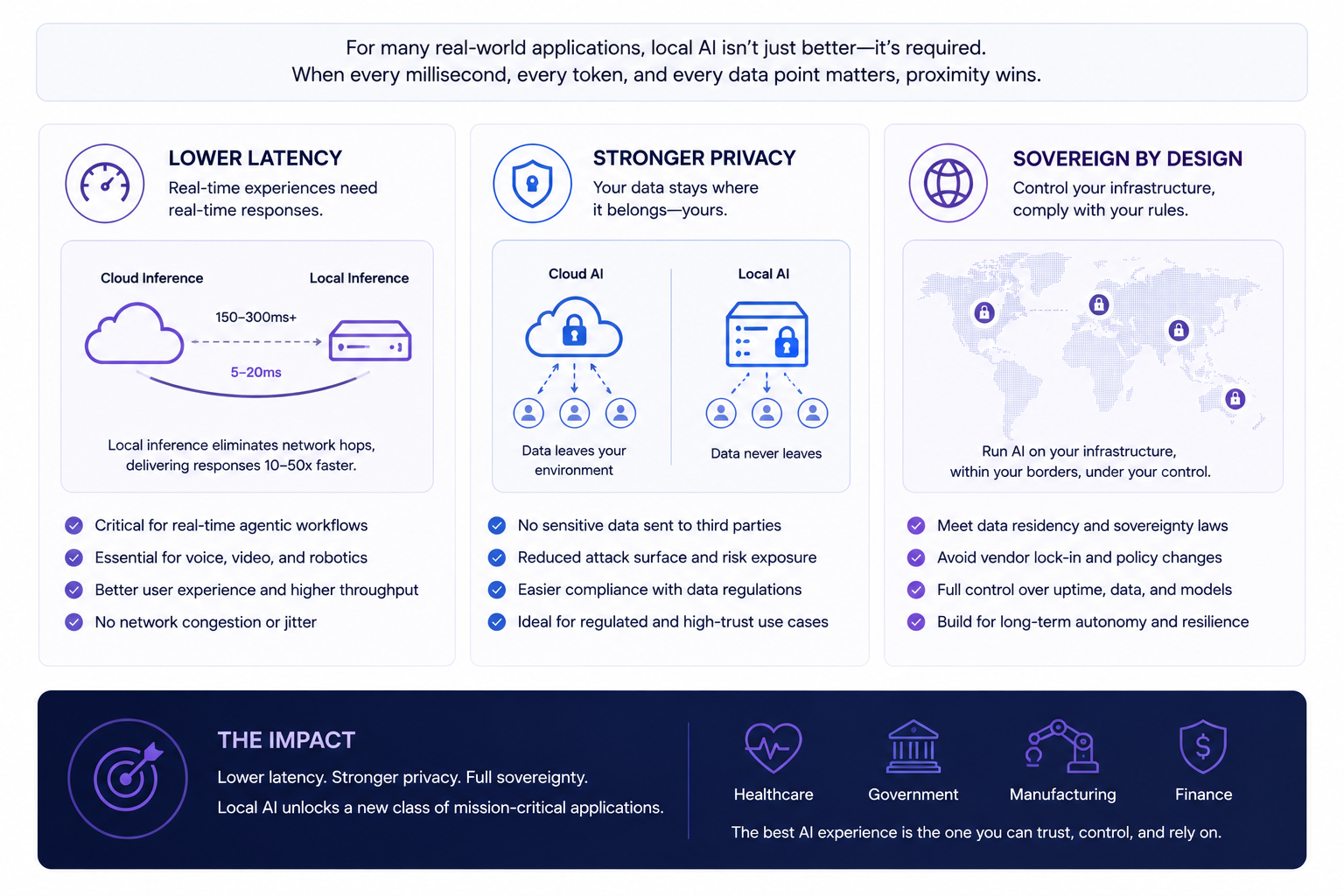
Latency-sensitive systems increasingly benefit from local inference because removing network round-trips creates much faster interactions. This matters for voice systems, copilots, robotics, industrial automation, gaming, and real-time interfaces.
Privacy is another major driver.
Many organizations simply do not want sensitive internal data constantly leaving their infrastructure. Healthcare providers, financial institutions, governments, and regulated enterprises are increasingly exploring on-prem or sovereign AI deployments specifically because of compliance and data residency concerns.
There is also a geopolitical dimension emerging around AI infrastructure.
Countries and enterprises increasingly view compute capacity as a strategic asset. Sovereign AI initiatives are growing rapidly as organizations attempt to reduce dependence on external providers and centralized infrastructure ecosystems.
In this environment, local and hybrid AI architectures become strategically important - not just technically interesting.
Open Models Are Changing The Competitive Landscape
A few years ago, the assumption was that proprietary models would maintain overwhelming long-term advantages due to scale, data access, and compute resources.
But open-weight ecosystems evolved much faster than expected. The gap between open and proprietary systems still exists, especially at the frontier. However, the practical usability gap for many production workloads has narrowed dramatically. And in infrastructure markets, “good enough” often scales faster than “best possible.”
This has happened repeatedly throughout computing history. Open ecosystems benefit from:
Rapid iteration
Community optimization
Hardware experimentation
Customization
Fine-tuning flexibility
Lower deployment friction
Reduced vendor lock-in
The result is that many organizations are no longer evaluating models solely based on benchmark leadership.
They are evaluating deployment flexibility, cost structure, operational control, and ecosystem maturity.
That changes the market completely.
The Hardware Story Is Just Beginning
Ironically, the software side of AI may currently be advancing faster than the hardware accessibility side.
While modern open models are becoming extremely capable, deploying them efficiently at scale still requires meaningful infrastructure investment once workloads grow beyond hobbyist usage.
There remains a major gap between:
Consumer AI hardware & Hyperscaler-grade AI infrastructure.
This gap is likely where the next major wave of innovation will occur. Inference-focused GPU systems, AI PCs, edge accelerators, memory optimization technologies, and specialized inference silicon will likely become one of the most important sectors in computing over the next five years.
Inference demand itself may ultimately exceed training demand in aggregate scale.
Training happens periodically.
Inference happens continuously.
And as AI becomes integrated into everyday software systems, persistent inference workloads will explode globally.
How Qubrid AI Supports Hybrid AI Deployment
As AI infrastructure becomes increasingly workload-aware, organizations need more than just access to models. They need flexible deployment options that match different operational requirements across latency, scale, privacy, and cost.
At Qubrid AI, we are building infrastructure around this shift toward hybrid AI deployment architectures.
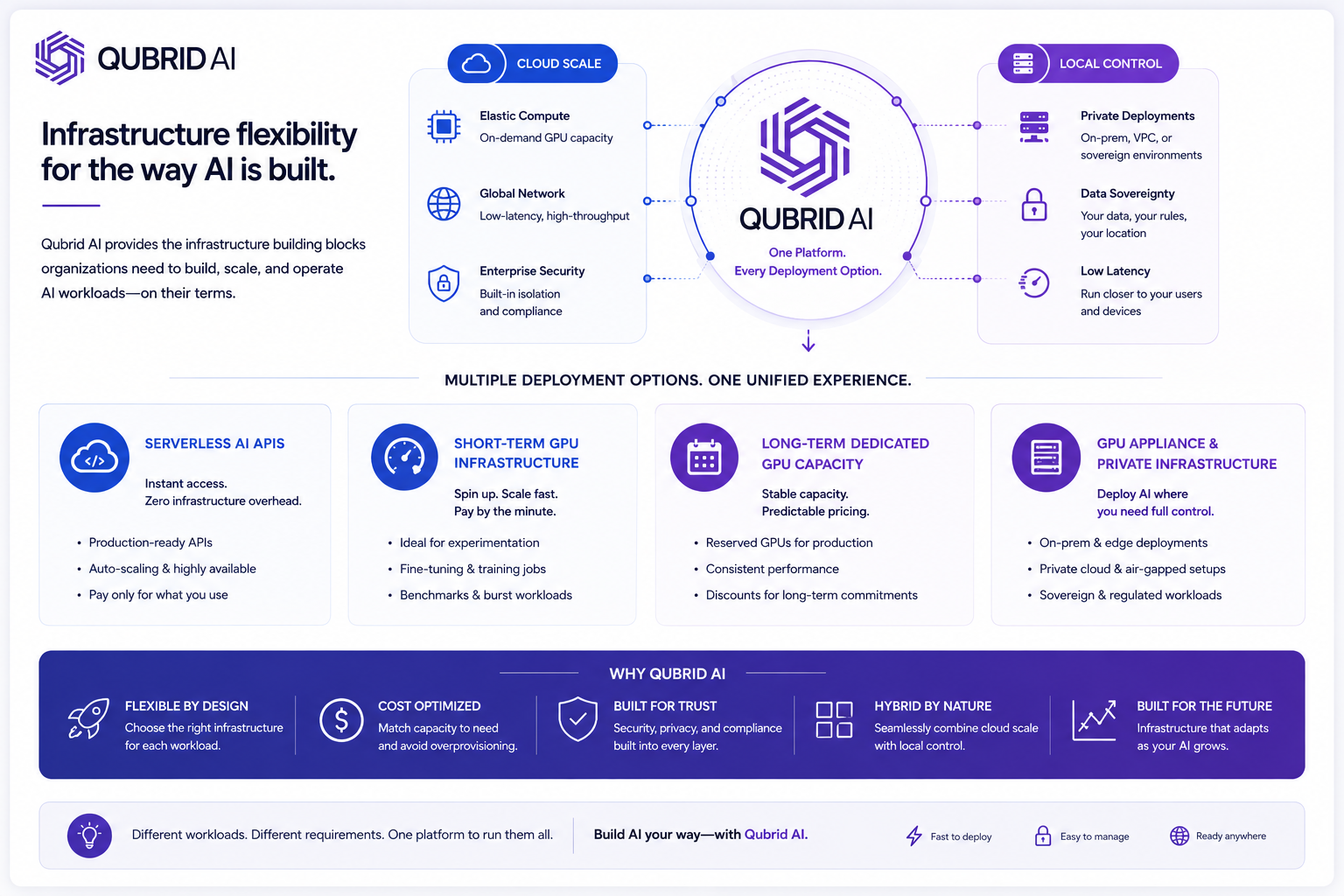
Different AI workloads require different infrastructure strategies.
Some teams prioritize:
rapid deployment through serverless inference APIs
burst GPU capacity for experimentation and short-term workloads
dedicated long-term GPU infrastructure for production scaling
private AI deployments with local control and data sovereignty
Increasingly, organizations need combinations of all of these simultaneously.
Qubrid AI supports multiple deployment models across the AI stack, including:
Serverless AI APIs
For teams that want fast access to AI inference without managing infrastructure complexity.
Short-Term GPU Infrastructure
Ideal for experimentation, fine-tuning, temporary scaling, benchmarking, and burst workloads.
Long-Term Dedicated GPU Capacity
Designed for production environments that require stable performance, predictable pricing, and infrastructure continuity.
GPU Appliance & Private AI Infrastructure
For organizations deploying AI workloads in private environments, on-prem infrastructure, sovereign AI deployments, or latency-sensitive systems.
As AI adoption scales, we believe infrastructure flexibility will become one of the most important competitive advantages in the industry.
The future of AI is unlikely to belong entirely to centralized cloud APIs or entirely to local inference.
It will belong to platforms capable of intelligently supporting both.
What The Next Five Years Probably Look Like
The most likely future is not one where local AI replaces cloud AI. It is one where AI systems become increasingly distributed, workload-aware, and dynamically optimized.
Organizations will likely operate across multiple layers simultaneously:
Edge inference for latency-sensitive systems
Local inference for repetitive and privacy-sensitive workloads
Cloud inference for frontier reasoning
Dynamic routing systems for optimization
Specialized models for domain-specific tasks
The companies that succeed will not necessarily be the ones with access to the single smartest model. They will be the ones that design the smartest infrastructure architectures. That is the real shift happening underneath the AI industry right now.
The conversation is no longer just about intelligence. It is increasingly about orchestration, economics, deployment strategy, and infrastructure efficiency. And that shift may ultimately matter more than any single model release.


