DeepSeek-V4-Pro: Architecture, Benchmarks & API on Qubrid AI
👉 Try DeepSeek-V4-Pro on the Qubrid AI platform: https://platform.qubrid.com/model/deepseek-v4-pro
The open-source leaderboard just got reshuffled again. DeepSeek-V4-Pro, the latest flagship from DeepSeek AI, has arrived with a claim that's hard to ignore: 1.6 trillion parameters, a 1 million token context window, and benchmark numbers that rival the best closed-source models on the planet. For developers who care about what's actually happening at the frontier of open-weight AI, this one deserves a close look.
In this post, we break down what DeepSeek-V4-Pro is, how its architecture works, what the benchmarks actually mean, and how you can start using it on Qubrid AI.
What is DeepSeek-V4-Pro?
DeepSeek-V4-Pro is the larger of two models in DeepSeek's new V4 series alongside DeepSeek-V4-Flash. It is a Mixture-of-Experts (MoE) language model with 1.6 trillion total parameters, of which only 49 billion are activated per token during inference. This makes it far more compute-efficient than its raw parameter count suggests.
The model was pre-trained on over 32 trillion high-quality tokens and supports a context window of 1,000,000 tokens, a significant leap that opens the door to use cases such as full codebase analysis, long-form document processing, and deep conversation memory. DeepSeek-V4-Pro ships under the MIT license, making it fully open for commercial use.
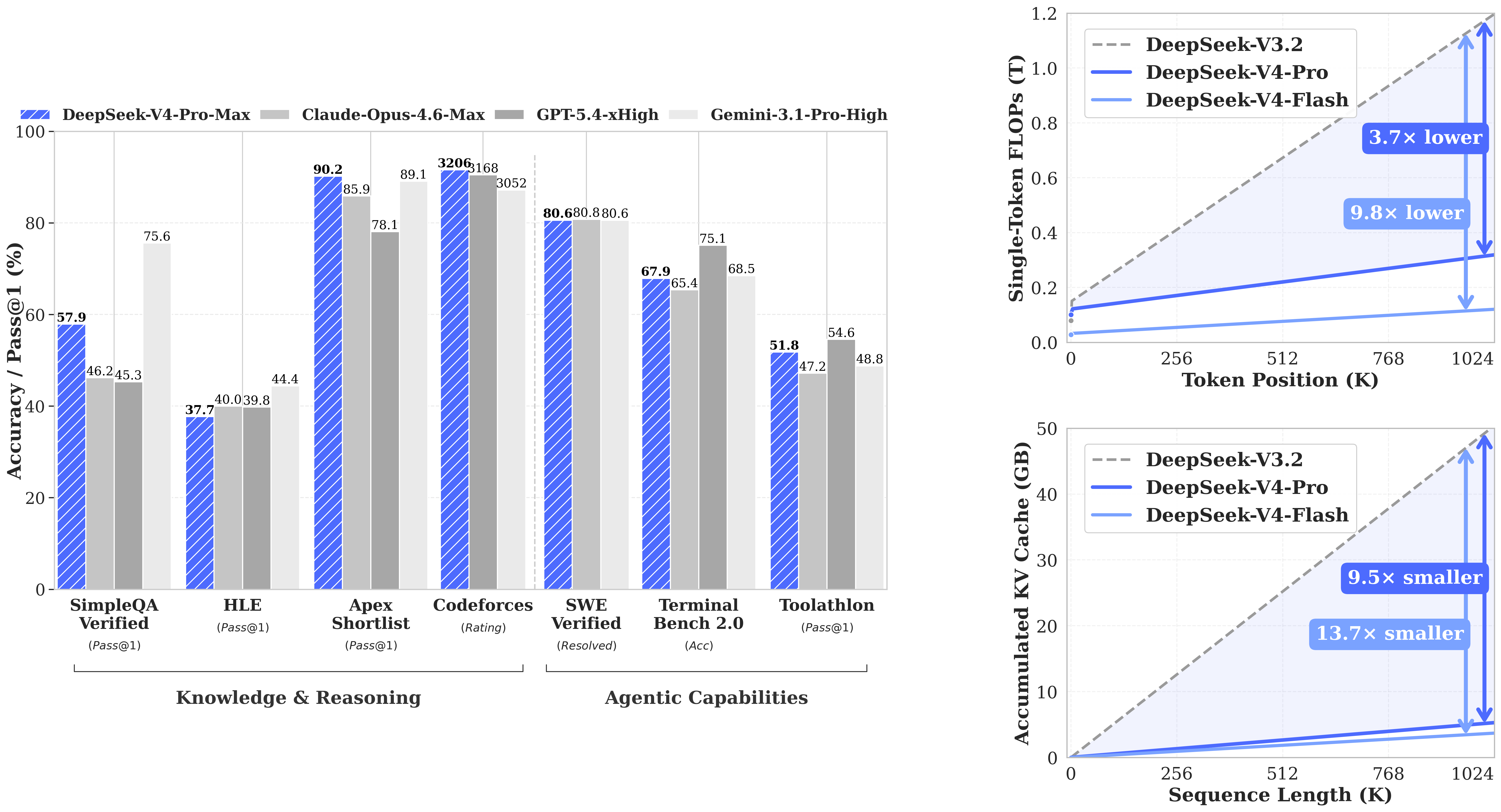
Its top reasoning mode, DeepSeek-V4-Pro-Max, is currently the best-performing open-source model available, particularly standing out in competitive coding, where it leads all models with a Codeforces rating of 3206.
👉 Try DeepSeek-V4-Pro on the Qubrid AI platform: https://platform.qubrid.com/model/deepseek-v4-pro
Key Specifications
Feature | Specification |
|---|---|
Total Parameters | 1.6 Trillion |
Activated Parameters | 49B per token |
Architecture | Mixture-of-Experts (MoE) |
Context Window | 1 Million tokens |
Precision | FP4 + FP8 Mixed |
Pre-training Tokens | 32T+ |
Reasoning Modes | Non-Think, Think High, Think Max |
License | MIT |
How the Hybrid MoE Architecture Works
DeepSeek-V4-Pro is not just a bigger version of what came before. It introduces three key architectural innovations that set it apart from earlier MoE models.
Hybrid Attention - CSA + HCA: Standard attention mechanisms become extremely expensive at very long contexts. DeepSeek-V4-Pro addresses this with a combination of Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA). The result is dramatic: at a 1M token context, the model requires only 27% of the single-token inference FLOPs and just 10% of the KV cache compared to its predecessor DeepSeek-V3.2. Long context is no longer a luxury; it's practical.
Manifold-Constrained Hyper-Connections (mHC): Deep neural networks can suffer from unstable signal propagation across layers, which leads to degraded training and unpredictable outputs. DeepSeek-V4-Pro incorporates mHC as a stronger alternative to standard residual connections, maintaining signal stability without sacrificing the model's expressive power.
Muon Optimizer: Training at a trillion-parameter scale requires careful optimization. The Muon optimizer enables faster convergence and greater training stability compared to standard AdamW approaches, allowing the team to push training further without diminishing returns.
Post-training follows a two-stage approach: domain-specific expert cultivation through supervised fine-tuning and reinforcement learning with GRPO, followed by unified model consolidation via on-policy distillation, merging specialized expertise into a single coherent model.
Simplified Flow
Input Tokens (up to 1M)
│
Hybrid Attention Layer
(CSA + HCA combined)
│
Gating Network
│
Select Top Experts
(from large expert pool)
│
Process Through Active Experts
(49B activated out of 1.6T)
│
mHC Residual Connection
│
Combine Expert Outputs
│
Reasoning Mode Applied
(Non-Think / Think High / Think Max)
│
Final Prediction
Key Features
1. Three Reasoning Modes DeepSeek-V4-Pro supports three selectable inference modes. Non-Think delivers fast, intuitive responses ideal for routine tasks. Think High applies conscious logical analysis for complex problem-solving. Think Max pushes the model to its absolute reasoning limit, using an extended chain-of-thought for research-grade problems. Each mode trades off speed for depth in a controlled, predictable way.
2. Million-Token Context With a 1M token context window, DeepSeek-V4-Pro can hold an entire large codebase, multiple long documents, or extended conversation histories in a single prompt. This is not just a technical headline; it fundamentally changes what kinds of applications are feasible to build.
3. Compute-Efficient MoE Design Despite its enormous total parameter count, only 49B parameters are active per forward pass. Combined with the FP4 precision on MoE expert weights, this makes the model viable to serve at scale without requiring impractical amounts of GPU memory.
4. MIT License Open weights, commercial use allowed, no strings attached. This makes DeepSeek-V4-Pro one of the few frontier-scale models that developers can freely build on, fine-tune, and deploy in production environments.
Benchmark Performance
Coding
DeepSeek-V4-Pro-Max leads all models on competitive programming benchmarks. On LiveCodeBench, it scores 93.5% ahead of Gemini-3.1-Pro High (91.7%) and Claude Opus 4.6 Max (88.8%). On Codeforces, it reaches a rating of 3206, the highest among all models tested, including GPT-5 (3168) and Gemini (3052). For developers building code generation, debugging tools, or autonomous dev agents, these numbers are significant.
Reasoning and Math
On GPQA Diamond, DeepSeek-V4-Pro-Max scores 90.1%, competitive with GPT-5 (93.0%) and Claude Opus 4.6 (91.3%). On HMMT 2026 Feb, it reaches 95.2%, and on IMOAnswerBench it scores 89.8%, trailing only GPT-5 (91.4%) among all frontier models. On the base model benchmarks, it scores 90.1% on MMLU and 64.5% on MATH, consistently outperforming DeepSeek-V3.2 across knowledge and reasoning tasks.
Long Context
DeepSeek-V4-Pro-Max scores 83.5% on MRCR-1M and 62.0% on CorpusQA-1M, both evaluated at a full 1 million token context length. These scores represent real retrieval and comprehension ability over extremely long inputs, not just theoretical window support.
Agentic Tasks
On SWE-bench Verified, DeepSeek-V4-Pro-Max achieves 80.6% matching Claude Opus 4.6 Max and Gemini-3.1-Pro High. On Terminal Bench 2.0, it scores 67.9%, and on MCPAtlas Public, it reaches 73.6%. This confirms that the model is not just strong at benchmarks; it performs in the kinds of tool-use and workflow settings that matter for real agent applications.
Built for Agent Workflows
DeepSeek-V4-Pro's combination of long context, strong tool-use performance, and multi-step reasoning makes it a natural fit for agentic applications. Its top scores on benchmarks like MCPAtlas, SWE-bench, and BrowseComp (83.4%) demonstrate that it can plan actions, navigate tool environments, and complete multi-step tasks with high reliability.
The model's three reasoning modes also give developers fine-grained control: use Non-Think for fast tool dispatch decisions, Think High for complex planning, and Think Max for research-level autonomous tasks that require deep deliberation before acting.
Getting Started on Qubrid AI
Step 1: Create a Qubrid AI Account: Sign up at qubrid.com. Start with a $5 top-up and get $1 in free tokens to explore models and run real workloads, no infrastructure setup needed.
Step 2: Try the Playground: Open the Qubrid Playground, select DeepSeek-V4-Pro from the model list, and start testing prompts directly in your browser. Experiment with temperature settings, token limits, and reasoning modes to find the best configuration for your use case.

Step 3: Integrate via API: Once you're ready to build, use Qubrid's OpenAI-compatible API to integrate DeepSeek-V4-Pro into your application:
from openai import OpenAI
# Initialize the OpenAI client with Qubrid base URL
client = OpenAI(
base_url="https://platform.qubrid.com/v1",
api_key="QUBRID_API_KEY",
)
stream = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V4-Pro",
messages=[
{
"role": "user",
"content": "Summarize this support ticket into bullet-point next steps for the agent."
}
],
max_tokens=393216,
temperature=1,
top_p=1,
stream=True
)
for chunk in stream:
if chunk.choices and chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
print("\n")The familiar API structure means you can drop it into existing workflows with minimal changes.
Practical Use Cases
Large Codebase Analysis: Feed an entire repository into DeepSeek-V4-Pro's 1M context window and ask it to identify bugs, suggest refactors, or generate documentation without chunking or retrieval hacks.
Autonomous Developer Agents: Pair its strong SWE-bench performance with tool-use frameworks to build agents that can plan, write, test, and iterate on code with minimal human intervention.
Long Document Intelligence: Process full legal contracts, research papers, or technical manuals in a single prompt. The model retains coherence across extremely long inputs.
Competitive Programming & Math: With a Codeforces rating of 3206 and strong MATH scores, it is well-suited for educational platforms, competitive coding tools, and mathematical reasoning applications.
Enterprise Knowledge Workflows: Build internal assistants that can read through large volumes of documentation, answer questions with high factual accuracy, and reason about complex multi-step processes.
Why Developers Use Qubrid AI
Qubrid AI gives developers direct access to frontier models without the complexity of managing their own GPU infrastructure.
No hardware setup: Run trillion-parameter models instantly through the platform.
Fast inference: High-performance GPU infrastructure for low-latency responses.
Unified API: Access multiple models with the same OpenAI-compatible pattern.
Playground to production: Test prompts interactively, then deploy the same configuration via API.
Transparent pricing: Start small with a $5 top-up and scale as your usage grows.
👉 Explore all available models at platform.qubrid.com/models
Our Thoughts
DeepSeek-V4-Pro is a genuine milestone for open-source AI. The combination of a 1M-token context, compute-efficient MoE design, and benchmark results that compete with the best closed-source models makes it one of the most capable openly licensed models ever released.
For developers, the practical implications are clear. Applications that were previously only possible with proprietary APIs, deep code analysis, long-document intelligence, and capable autonomous agents are now buildable on a model with an MIT license and a strong, active research team behind it.
The Codeforces lead alone makes it the most interesting model for engineering-focused applications right now. And with the Think Max reasoning mode pushing capabilities even further, DeepSeek-V4-Pro isn't just competitive, it's leading in the benchmarks that matter most for production AI workflows.
👉 Try DeepSeek-V4-Pro on the Qubrid AI platform: https://platform.qubrid.com/model/deepseek-v4-pro


