Launch Faster AI Applications with DeepSeek V4 Flash on Qubrid AI
👉 Try DeepSeek-V4-Flash on the Qubrid AI platform: https://platform.qubrid.com/playground?model=deepseek-v4-flash
If you’ve been waiting for a model that doesn’t make you choose between speed and intelligence, DeepSeek V4 Flash might be exactly what you’ve been looking for. Built on the same architectural lineage as DeepSeek V3 and the newly released DeepSeek V4 Pro, V4 Flash is optimized for developers who need rapid, reliable responses without sacrificing reasoning depth. It’s lean, it’s quick, and it’s now available on Qubrid AI.
What is DeepSeek V4 Flash?
DeepSeek V4 Flash is a high-speed, instruction-tuned large language model developed by DeepSeek AI. It belongs to the DeepSeek V4 family, a generation of models engineered for both performance and efficiency. While DeepSeek V4 Pro pushes the ceiling on raw capability, V4 Flash is purpose-built for latency-sensitive applications, agentic pipelines, and high-throughput workloads where response time matters as much as answer quality.
Think of it as the model you reach for when you need thousands of calls per day, real-time user interactions, or fast iteration in development without spinning up infrastructure that breaks your budget.
👉 Try DeepSeek-V4-Flash on the Qubrid AI platform: https://platform.qubrid.com/playground?model=deepseek-v4-flash
Key Specifications
Feature | Details |
|---|---|
Model Name | DeepSeek V4 Flash |
Model Family | DeepSeek V4 |
Architecture | Mixture-of-Experts (MoE) with MLA |
Context Window | 128K tokens |
Optimization | Speed and throughput |
Instruction Tuning | Yes |
Availability | Qubrid AI Platform |
API Access | Yes, via Qubrid AI |
How the Architecture Works
DeepSeek V4 Flash inherits the architectural innovations that made the V4 family notable: a Mixture-of-Experts (MoE) design paired with Multi-head Latent Attention (MLA). These two components work together to deliver both efficiency and performance.
In a standard dense transformer, every parameter activates for every token, computationally expensive and slow at scale. DeepSeek’s MoE approach changes that. The model routes each token through only a subset of specialized "expert" sub-networks, activating a fraction of total parameters per forward pass. This means V4 Flash can maintain a large effective parameter count while keeping inference fast and resource-light.
MLA further reduces the memory footprint during inference by compressing the key-value cache into a lower-dimensional latent space. Instead of storing full attention matrices, the model works with compact representations that are projected back when needed. The result is significantly lower memory usage without degrading attention quality.
Simplified Flow
Input Tokens
↓
Tokenization & Embedding
↓
MLA (Multi-head Latent Attention)
→ Compress KV cache into latent space
→ Attend efficiently over 128K context
↓
MoE Router
→ Select top-K expert networks per token
→ Only active experts compute forward pass
↓
Expert FFN Layers (sparse activation)
↓
Output Projection → Response Tokens
This architecture is what makes V4 Flash genuinely fast,t not just marketed as fast.
Key Features
1. 128K Token Context Window
V4 Flash supports up to 128,000 tokens of context, enabling long document analysis, multi-turn agent memory, and complex code reasoning across large codebases, es all within a single call.
2. MoE Sparse Activation
By activating only the relevant expert sub-networks per token, V4 Flash dramatically reduces compute per inference step. You get the reasoning depth of a large model at the cost profile of a smaller one.
3. Multi-head Latent Attention (MLA)
MLA compresses the KV cache during inference, reducing memory overhead and enabling faster throughput, especially important in high-concurrency production environments.
4. Instruction-Tuned for Real Tasks
V4 Flash is fine-tuned to follow complex, multi-step instructions reliably. Whether you’re building a customer support bot, a code assistant, or a document processor, it handles structured prompts with consistency.
5. API-First Design
The model is built for programmatic access. Clean, predictable outputs make it straightforward to integrate into existing pipelines without extensive post-processing.
Benchmark Performance
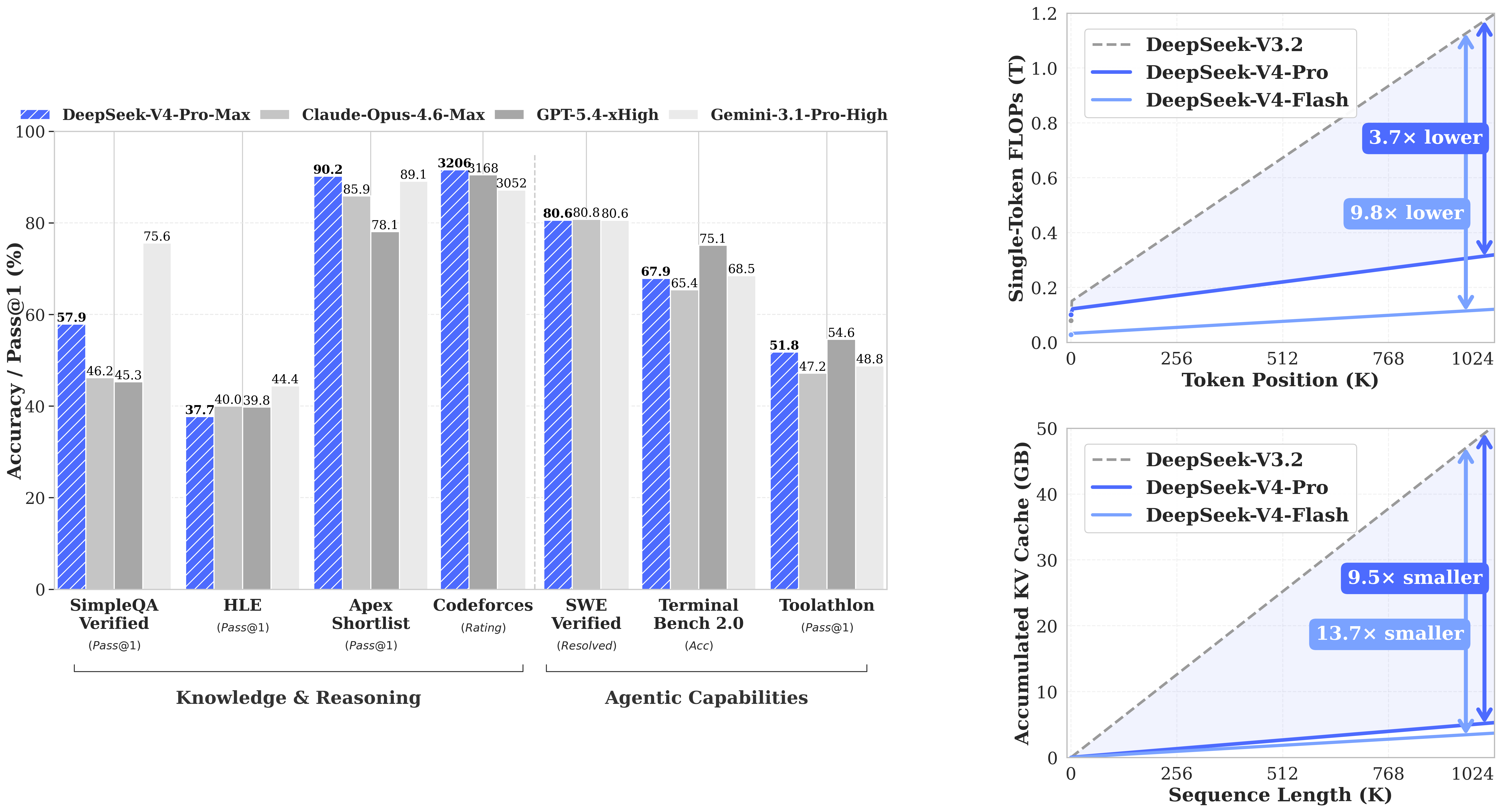
Reasoning & General Intelligence
DeepSeek V4 Flash performs competitively on standard reasoning benchmarks, holding its own against models significantly larger in active parameter count. Its MoE design allows it to punch above its weight on tasks requiring multi-step logical inference.
Coding
On coding benchmarks, V4 Flash demonstrates strong performance across Python, JavaScript, and systems languages. It handles code generation, debugging, and explanation tasks with accuracy that makes it practical for developer tooling.
Mathematics
Mathematical reasoning is a known strength of the DeepSeek V4 family. V4 Flash inherits this capability, performing well on competition-style math problems and step-by-step derivations.
Long-Context Tasks
With 128K context support, V4 Flash handles document summarization, retrieval-augmented tasks, and long-form analysis without the degradation seen in models with shorter windows.
For detailed benchmark numbers and comparisons, refer to the official DeepSeek V4 Pro benchmark page on Hugging Face as a reference for the V4 family’s performance profile.
Built for Agent Workflows
DeepSeek V4 Flash is particularly well-suited for agentic use cases and scenarios where a model must plan, call tools, interpret results, and iterate across multiple steps.
Its low latency makes it viable as an orchestrator model in multi-agent systems, where speed at each reasoning step compounds into dramatically faster end-to-end task completion. Its large context window means agents can carry rich state across long task horizons without losing track of earlier steps.
If you’re building with frameworks like LangChain, LlamaIndex, or custom agent loops, V4 Flash fits naturally as the backbone model, fast enough to keep pipelines responsive, capable enough to handle complex tool-use reasoning.
Getting Started on Qubrid AI
Step 1: Access the Playground
Head to the Qubrid AI Playground and select DeepSeek V4 Flash from the model menu. You can start prompting immediately, no setup required. Test your use case, explore the model’s behavior, and get a feel for its response style before committing to integration.

Step 2: Generate Your API Key
Once you’re ready to integrate, navigate to your Qubrid AI dashboard and generate an API key. Qubrid AI provides OpenAI-compatible endpoints, so if you’ve built with any major LLM provider before, the integration pattern will feel familiar. Minimal code changes, maximum compatibility.
Python example:
from openai import OpenAI
# Initialize the OpenAI client with Qubrid base URL
client = OpenAI(
base_url="https://platform.qubrid.com/v1",
api_key="QUBRID_API_KEY",
)
stream = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V4-Flash",
messages=[
{
"role": "user",
"content": "Summarize this support ticket into bullet-point next steps for the agent."
}
],
max_tokens=393216,
temperature=1,
top_p=1,
stream=True
)
for chunk in stream:
if chunk.choices and chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
print("\n")Step 3: Deploy and Scale
With your API key in hand, swap DeepSeek V4 Flash into your application. Qubrid AI handles the infrastructure model serving, scaling, and uptime so you can focus on building. Whether you’re running a handful of calls during development or millions in production, the platform scales with you.
Practical Use Cases
Customer Support Automation: V4 Flash’s speed makes it ideal for real-time chat interfaces. Fast responses keep users engaged; the 128K context keeps conversations coherent across long sessions.
Code Review and Generation: Integrate V4 Flash into your CI/CD pipeline or IDE extension for on-demand code suggestions, review comments, and documentation generation.
Document Intelligence: Feed in long contracts, research papers, or internal reports and extract structured summaries, key clauses, or specific data points at scale.
Agentic Research Tools: Use V4 Flash as the reasoning core of an agent that searches, synthesizes, and reports, iterating through tool calls faster than heavier models allow.
Rapid Prototyping: When you need to test product ideas quickly, V4 Flash lets you iterate on prompts and outputs without the latency overhead that slows down experimentation.
Why Developers Use Qubrid AI
Qubrid AI exists to give developers direct, reliable access to frontier models without the overhead of managing infrastructure or navigating opaque pricing. You get clean API access, transparent usage, and a platform designed for builders, not just enterprise procurement teams.
With DeepSeek V4 Flash now available, Qubrid AI adds another high-performance option to a growing model library that lets you pick the right tool for the right job. Fast and efficient for high-volume tasks, powerful for complex reasoning, the choice is yours, and switching is as simple as changing a model parameter.
Our Thoughts
DeepSeek V4 Flash represents something genuinely useful in the current model landscape: a capable, fast model that doesn’t require you to over-provision compute or accept sluggish response times as the cost of intelligence. The MoE architecture and MLA attention mechanism aren’t marketing language; they translate directly into real-world performance gains that matter when you’re building production systems.
For developers building agentic workflows, high-throughput APIs, or latency-sensitive user-facing products, V4 Flash is worth serious consideration. And with Qubrid AI handling the deployment side, the path from "I want to try this" to "this is running in production" is shorter than ever.
👉 Try DeepSeek-V4-Flash on the Qubrid AI platform: https://platform.qubrid.com/playground?model=deepseek-v4-flash


