Qwen3.6-27B Explained: Agentic Coding, Hybrid Architecture, Benchmarks & API on Qubrid AI
A 27-billion-parameter model that beats 400B-class systems on coding benchmarks shouldn't exist. Qwen3.6-27B does.
Alibaba's Qwen team just released the first open-weight model from the Qwen3.6 series, and it's turning heads for one reason: a compact dense model is now outperforming much larger Mixture-of-Experts systems on the benchmarks that developers actually care about, real-world software engineering, agentic coding, and frontier-level reasoning.
No MoE routing overhead, no inflated parameter budgets. Just 27B dense parameters, a rethought hybrid architecture, and a 262K token native context window.
For developers, the best part is straightforward: you don't need specialized hardware. Through Qubrid AI, you can instantly experiment with Qwen3.6-27B using a web playground or integrate it into your applications via API.
In this guide, we'll explore what Qwen3.6-27B is, how its hybrid architecture works, its benchmark performance, its standout Thinking Preservation feature, and how you can start using it on Qubrid AI.
What is Qwen3.6-27B?
Qwen3.6-27B is a dense causal language model with an integrated vision encoder, released by Alibaba's Qwen team in April 2026. It is the first open-weight release from the Qwen3.6 series, built directly on community feedback from Qwen3.5, and is purpose-built for agentic coding, frontend reasoning, and repository-level software engineering.
Unlike MoE models that distribute computation across sparse expert networks, Qwen3.6-27B activates all 27 billion parameters on every token. This makes it architecturally simpler to deploy while delivering accuracy that rivals models several times its size.
It introduces two headline capabilities not present in previous Qwen releases: a hybrid attention mechanism combining Gated DeltaNet linear attention with standard Gated Attention, and a Thinking Preservation feature that retains reasoning traces across multi-turn agent sessions,s directly addressing one of the most common failure modes in production agentic workflows.
👉 You can try Qwen3.6-27B on Qubrid AI here: https://platform.qubrid.com/model/qwen3.6-27b
Key Specifications
Feature | Specification |
|---|---|
Total Parameters | 27B |
Architecture | Dense Causal LM + Vision Encoder |
Number of Layers | 64 |
Attention Mechanism | Hybrid: Gated DeltaNet + Gated Attention |
Linear Attention Heads | 48 (V), 16 (QK) |
Standard Attention Heads | 24 (Q), 4 (KV) |
Feed Forward Intermediate Dim | 17,408 |
Token Embedding | 248,320 (padded) |
Native Context Length | 262,144 tokens |
Extended Context (YaRN) | Up to 1,010,000 tokens |
Speculative Decoding | Multi-Token Prediction (MTP) |
License | Apache 2.0 |
Focus Areas | Agentic coding, vision-language, long-context reasoning |
The model's hybrid layout repeats a distinctive pattern across 64 layers: every group of 4 layers contains 3 Gated DeltaNet blocks followed by 1 standard Gated Attention block. This ratio is deliberate linear attention handles long-range context efficiently, while standard attention anchors precise token-level reasoning at regular intervals.
How the Hybrid Attention Architecture Works
To understand why Qwen3.6-27B punches above its weight class, it helps to understand what makes its attention architecture different from a standard transformer.
Traditional transformers use full self-attention on every layer, which scales quadratically with sequence length expensive at 262K tokens. Pure linear attention models are more efficient but often lose precision on tasks requiring sharp, token-specific reasoning. Qwen3.6-27B solves this by combining both in a single model.
Simplified Flow
Input Token
│
Gated DeltaNet (Linear Attention) ×3
│ ← Handles long-range dependencies efficiently
│
Gated Attention (Standard) ×1
│ ← Anchors precise, token-level reasoning
│
Feed Forward Network (dim 17,408)
│
Repeat across 64 layers
│
Final Prediction
The Gated DeltaNet layers use a delta-rule update mechanism with a learned gating function, allowing the model to selectively update its recurrent state based on relevance, more like an efficient memory system than a sliding window. The standard Gated Attention layer that follows every three linear layers acts as a correction pass, catching anything the linear layers may have smoothed over.
This design offers several advantages:
Long-context efficiency: Linear attention in the majority of layers keeps memory and compute manageable at 262K+ tokens.
Reasoning precision: Standard attention at regular intervals preserves accuracy on tasks requiring exact token relationships.
Scalable context extension: YaRN scaling can extend context to 1,010,000 tokens without full architectural retraining.
Throughput gains: Multi-Token Prediction (MTP) enables speculative decoding for significantly improved inference throughput in production.
Key Features of Qwen3.6-27B
1. Agentic Coding & Repository-Level Reasoning
Qwen3.6-27B was specifically trained to improve on the failure modes of Qwen3.5 in frontend and repository-level workflows. The model now handles multi-file reasoning, UI component generation, and codebase navigation with substantially higher fluency and consistency.
On SWE-bench, verified the most widely used benchmark for real-world software engineering agents, it scores 77.2, beating both Qwen3.5-27B (75.0) and the much larger Qwen3.5-397B-A17B (76.2). A 27B dense model outperforms a 400B MoE on software engineering tasks.
2. Thinking Preservation Across Agent Sessions
In most models, reasoning traces generated during earlier turns are discarded when the conversation continues. Each new step starts cold, leading to redundant re-reasoning and inconsistent decisions across long agent runs.
Qwen3.6-27B is trained to preserve and leverage thinking traces from historical messages. Enable it with "preserve_thinking": True In your API call, the model builds cumulative reasoning context across turns rather than resetting, reducing redundant token usage, improving decision consistency, and improving KV cache utilization in both thinking and non-thinking modes.
3. Native Vision-Language Understanding
Qwen3.6-27B is not a text-only model. Its integrated vision encoder handles images, charts, documents, and video natively with strong performance on spatial reasoning (RefSpatialBench: 70.0), chart understanding (CharXiv RQ: 78.4), OCR (CC-OCR: 81.2), and visual agent tasks (AndroidWorld: 70.3, V*: 94.7).
It also supports video understanding, scoring 87.7 on VideoMME with subtitles ahead of Claude 4.5 Opus (77.7).
4. 262K Native Context, Extensible to 1M+
With a 262,144-token native context window, Qwen3.6-27B can process entire repositories, long legal documents, extended agent histories, or multi-document research inputs in a single pass. For tasks where even that isn't enough, YaRN scaling extends the effective context to 1,010,000 tokens.
The Qwen team recommends maintaining at least 128K context when using the model for complex reasoning tasks, as the model leverages extended context to enhance thinking quality.
Benchmark Performance
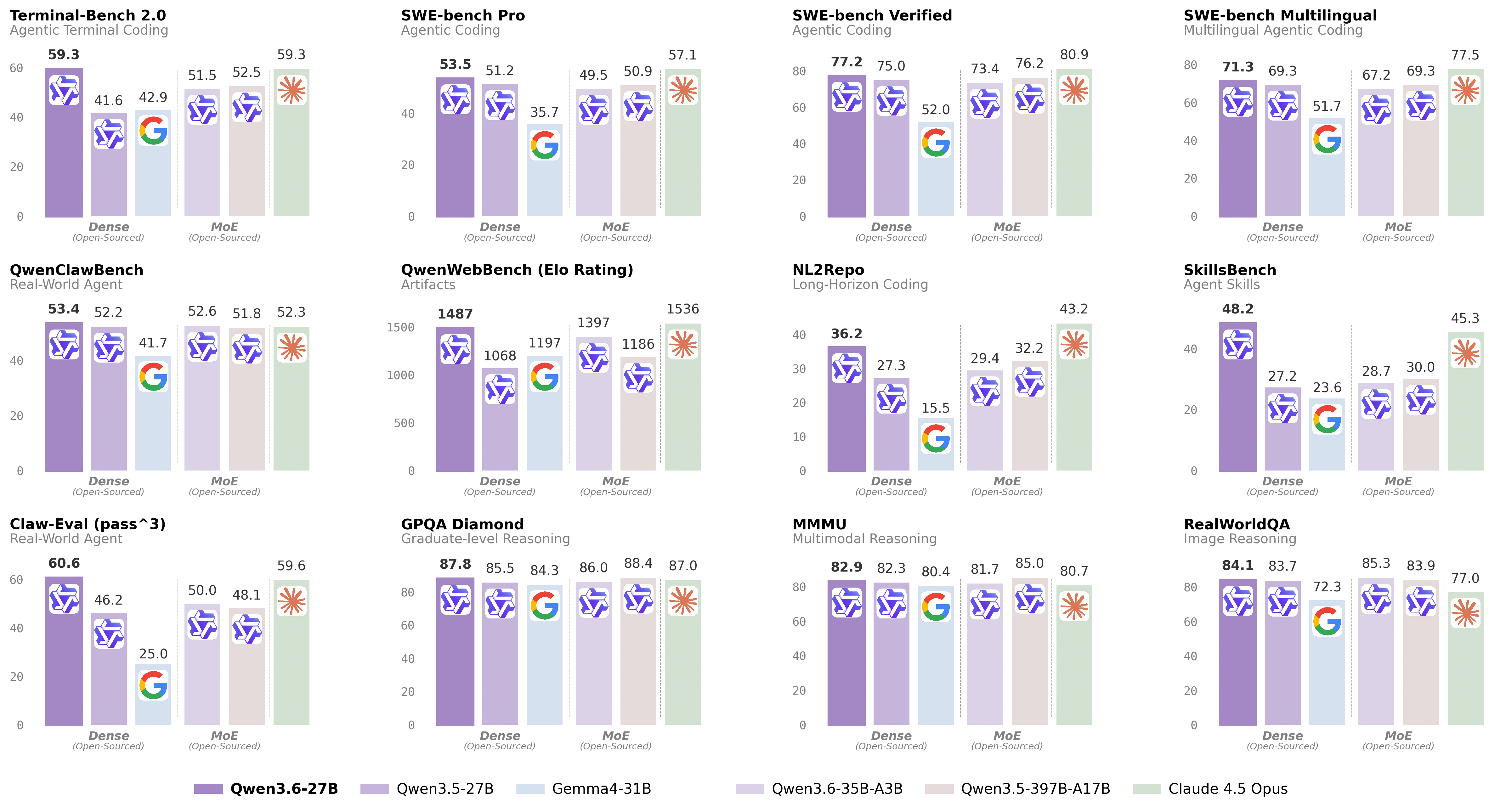
Qwen3.6-27B has been evaluated across coding, reasoning, knowledge, and vision-language benchmarks, compared against Qwen3.5-27B, Qwen3.5-397B-A17B, Gemma4-31B, Claude 4.5 Opus, and Qwen3.6-35B-A3B.
For complete benchmark methodology and evaluation configurations, refer to the official model page: 👉 https://qwen.ai/blog?id=qwen3.6-27b
Coding Tasks
Benchmark | Qwen3.5-27B | Qwen3.5-397B-A17B | Claude 4.5 Opus | Qwen3.6-27B |
|---|---|---|---|---|
SWE-bench Verified | 75.0 | 76.2 | 80.9 | 77.2 |
SWE-bench Pro | 51.2 | 50.9 | 57.1 | 53.5 |
SWE-bench Multilingual | 69.3 | 69.3 | 77.5 | 71.3 |
Terminal-Bench 2.0 | 41.6 | 52.5 | 59.3 | 59.3 |
SkillsBench Avg5 | 27.2 | 30.0 | 45.3 | 48.2 |
NL2Repo | 27.3 | 32.2 | 43.2 | 36.2 |
Claw-Eval Avg | 64.3 | 70.7 | 76.6 | 72.4 |
On SkillsBench, Qwen3.6-27B scores 48.2 outperforming Claude 4.5 Opus (45.3) and every Qwen3.5 model. On Terminal-Bench 2.0, it matches Claude 4.5 Opus exactly at 59.3.
Reasoning Tasks
Benchmark | Qwen3.5-27B | Claude 4.5 Opus | Qwen3.6-27B |
|---|---|---|---|
GPQA Diamond | 85.5 | 87.0 | 87.8 |
AIME 2026 | 92.6 | 95.1 | 94.1 |
LiveCodeBench v6 | 80.7 | 84.8 | 83.9 |
HMMT Feb 26 | 84.3 | 85.3 | 84.3 |
IMOAnswerBench | 79.9 | 84.0 | 80.8 |
Qwen3.6-27B scores 87.8 on GPQA Diamond, outperforming Claude 4.5 Opus (87.0) on graduate-level scientific reasoning. On AIME 2026, it scored 94.1, placing it among the strongest open models on current math competition benchmarks.
General Knowledge Tasks
Benchmark | Qwen3.5-27B | Claude 4.5 Opus | Qwen3.6-27B |
|---|---|---|---|
MMLU-Pro | 86.1 | 89.5 | 86.2 |
MMLU-Redux | 93.2 | 95.6 | 93.5 |
C-Eval | 90.5 | 92.2 | 91.4 |
Vision Language Tasks
Benchmark | Qwen3.5-27B | Claude 4.5 Opus | Qwen3.6-27B |
|---|---|---|---|
MMMU | 82.3 | 80.7 | 82.9 |
VideoMME (w/ sub.) | 87.0 | 77.7 | 87.7 |
AndroidWorld | 64.2 | — | 70.3 |
RefSpatialBench | 67.7 | — | 70.0 |
V* | 93.7 | 67.0 | 94.7 |
On VideoMME, Qwen3.6-27B (87.7) significantly outperforms Claude 4.5 Opus (77.7). On AndroidWorld,d a visual agent benchmark for autonomous device control reaches 70.3 with no comparable Claude score publicly available.
Built for Agent Workflows
Qwen3.6-27B is not just a stronger base model; it is designed specifically for production agentic use cases. Its key differentiators for agent workflows include:
Thinking Preservation: Reasoning chains carried forward across turns for consistent multi-step decision making
1M+ token context via YaRN: Full codebase or document ingestion in a single inference call
Native tool calling support: Full OpenAI-compatible function calling via the
qwen3_coderparser, optimized for agent scaffoldsMulti-Token Prediction (MTP): Speculative decoding for improved throughput in high-volume pipelines
Interleaved thinking mode: The model reasons before every response by default, with the option to disable for latency-sensitive tasks
This makes Qwen3.6-27B well suited for applications including:
Coding agents that navigate repositories, generate PRs, debug failing tests, and iterate autonomously
Frontend generation pipelines that produce web apps, data visualizations, games, and animations from natural language
Multimodal document pipelines that combine OCR, chart parsing, and structured data extraction
Long-horizon research agents that maintain coherent reasoning across extended multi-turn workflows
Visual automation agents that operate over video, screenshots, and UI interfaces
Getting Started with Qwen3.6-27B on Qubrid AI
Running frontier-class models locally requires expensive multi-GPU infrastructure. Qubrid AI simplifies this by providing immediate API access to Qwen3.6-27B through a managed platform, no hardware setup, no vLLM configuration, no GPU procurement.
Step 1: Create a Qubrid AI Account
Sign up on the Qubrid AI platform. Start with a $5 top-up and get $1 worth of tokens free to explore the platform and run real workloads.
Step 2: Use the Playground
The Qubrid Playground lets you interact with Qwen3.6-27B directly in your browser. Test prompts, adjust temperature and token limits, and explore its reasoning and vision capabilities, no code required.
Select qwen3.6-27b from the model list and start testing.
For coding tasks, use temperature=0.6, top_p=0.95, top_k=20.
For general reasoning tasks, use temperature=1.0, top_p=0.95, top_k=20.

Step 3: Integrate the API
Once you're ready to build, integrate Qwen3.6-27B using Qubrid's OpenAI-compatible API.
Python Example
from openai import OpenAI
client = OpenAI(
base_url="https://platform.qubrid.com/v1",
api_key="YOUR_QUBRID_API_KEY",
)
response = client.chat.completions.create(
model="qwen3.6-27b",
messages=[
{
"role": "system",
"content": "You are a helpful coding assistant."
},
{
"role": "user",
"content": "Review this function and suggest improvements with explanations."
}
],
temperature=0.6,
max_tokens=4096,
stream=True,
extra_body={
"top_k": 20,
"chat_template_kwargs": {"preserve_thinking": True}
}
)
for chunk in response:
if chunk.choices:
delta = chunk.choices[0].delta
if hasattr(delta, "content") and delta.content:
print(delta.content, end="", flush=True)
print("\n")
cURL Example
curl -X POST "https://platform.qubrid.com/v1/chat/completions" \
-H "Authorization: Bearer YOUR_QUBRID_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3.6-27b",
"messages": [
{"role": "user", "content": "Explain the tradeoffs between MoE and dense architectures."}
],
"temperature": 1.0,
"max_tokens": 4096
}'
Practical Use Cases
Qwen3.6-27B can power a wide range of demanding AI applications:
AI Coding Assistants: Agents that generate, debug, and patch code across multi-file repositories with full repository-level context
Frontend Generation Tools: Pipelines that convert design specs or natural language into web apps, games, SVGs, and data visualizations
Autonomous Research Agents: Systems that reason over long documents, synthesize information, and produce structured outputs
Enterprise Document Intelligence: OCR, chart parsing, and multimodal QA over PDFs and visual reports using the 262K context window
Visual Agent Pipelines: Automated workflows that operate over screenshots, video frames, and UI interfaces
Mathematical and Scientific Reasoning: STEM research assistance and applications requiring rigorous step-by-step logic
Why Developers Use Qubrid AI
Qubrid AI provides a practical way for developers to access frontier-class open models without infrastructure complexity.
Key advantages include:
No GPU setup required: Access 27B+ parameter models without managing hardware or drivers
Fast inference infrastructure: The platform runs on high-performance GPUs optimized for low latency
Unified OpenAI-compatible API: Multiple models accessible with the same API pattern, swap models by changing one field
Playground to production: Test prompts and parameters in the browser, then deploy the identical configuration via API
Full parameter support:
preserve_thinking,top_k,chat_template_kwargs, and all Qwen3.6-specific parameters are fully supported
👉 Explore all available models here: https://platform.qubrid.com/models
Our Thoughts
Qwen3.6-27B represents a meaningful shift in what open-weight models can deliver at the 27B scale.
Its hybrid Gated DeltaNet + standard attention architecture enables efficient processing of 262K+ token contexts without the complexity of MoE routing. Its Thinking Preservation feature directly addresses a real pain point for developers building multi-turn agent systems. And its benchmark results are hard to argue with: a 27B model outperforming 400B-class systems on SWE-bench, beating Claude 4.5 Opus on SkillsBench and GPQA Diamond, and matching it on Terminal-Bench 2.0.
For developers building coding agents, frontend generation tools, or complex multi-step reasoning pipelines, Qwen3.6-27B is one of the most capable open-weight models available today and one of the easiest to access on Qubrid.
👉 Try Qwen3.6-27B on Qubrid AI here: https://platform.qubrid.com/model/qwen3.6-27b
If you're evaluating open alternatives to proprietary frontier models for production agent workflows, this is definitely a model worth testing.


