GLM-5.2: The World's Leading Open-Weights LLM Is Now Live on Qubrid AI - A Complete Technical Deep Dive
TL;DR: GLM-5.2 by Z.ai is the most capable open-weights large language model available today - beating GPT-5.5 on multiple coding benchmarks, achieving near-parity with Claude Opus 4.8 on long-horizon agentic tasks, and carrying an MIT license that lets you self-host. Qubrid AI is a Day 0 launch partner with Z.ai, giving you immediate, production-ready API access to GLM-5.2 at industry-competitive pricing. This post covers every technical detail, benchmark, API integration guide, and pricing breakdown you need.
What Is GLM-5.2?
GLM-5.2 is Z.ai's (Zhipu AI) flagship foundation model, purpose-built for the era of long-horizon, multi-step autonomous tasks. It represents a substantial leap over its predecessor GLM-5.1 and currently holds the title of the #1 open-weights model on the Artificial Analysis Intelligence Index v4.1 with a score of 51 - a full 7 points ahead of MiniMax-M3 (44) and DeepSeek V4 Pro (44).

The model's defining capability is its genuinely usable 1-million-token context window. Unlike models that merely advertise extended context lengths, GLM-5.2 has undergone months of specialized training specifically for long-horizon coding agent scenarios - enabling it to maintain architectural coherence, track interface contracts, and preserve historical decisions across entire project-scale engineering sessions.
GLM-5.2 is not just an academic benchmark model. Before its public release, Z.ai made it available to select users, and the feedback from real-world developers shaped the final release:
Stronger project-level context capacity - an entire codebase fits in a single reasoning workflow
More stable long-horizon execution - complex multi-step tasks proceed without going off track
More reliable adherence to production engineering standards - hard constraints in team workflows are enforced
Stronger mobile & client-side engineering - goes beyond app generation to support a full on-device debugging loop
Qubrid AI × Z.ai: Day 0 Partnership
Qubrid AI is proud to announce our Day 0 partnership with Z.ai for the GLM-5.2 launch. This means:
GLM-5.2 is available on Qubrid AI today, with no waitlist
Production-grade API access from Day 0, with full streaming and function-calling support
Competitive, transparent per-token pricing (see Pricing)
Full support for the model's advanced features: Thinking Mode, Reasoning Effort Control, Context Caching, Structured Output, MCP, and Function Calling
Unified API interface - if you already use Qubrid AI, integrating GLM-5.2 is a one-line model string change
This partnership reflects Qubrid AI's commitment to giving developers and enterprises access to the most advanced open-source models at the moment they launch - not weeks later.
Model Architecture & Specifications
Specification | Value |
|---|---|
Model Name | GLM-5.2 |
Developer | Z.ai (Zhipu AI) |
Release Date | June 16–17, 2026 |
Architecture | Mixture-of-Experts (MoE) Transformer |
Total Parameters | 744B (same as GLM-5.1) |
Active Parameters | ~40B per forward pass |
Context Window | 1,000,000 tokens (1M) |
Maximum Output Tokens | 128,000 tokens (128K) |
Input Modalities | Text |
Output Modalities | Text |
License | MIT (fully open, self-hostable) |
Positioning | Flagship Foundation Model |
Architecture Notes:
GLM-5.2 uses a Mixture-of-Experts (MoE) design, which is central to its efficiency profile. Despite having 744B total parameters, only ~40B parameters are active at any given inference step. This means the model achieves frontier-level intelligence while maintaining a much lower per-token compute cost than comparable dense models - a key reason it undercuts closed-source competitors on price while matching them on capability.
This is the same parameter count as GLM-5.1, which means the performance gains in GLM-5.2 come entirely from training improvements rather than raw scale - including longer context specialization, improved instruction following, and enhanced long-horizon reasoning.
Context Window: 1M Tokens, Truly Usable
The 1M token context window in GLM-5.2 is perhaps the feature that most distinguishes it from the field - not because 1M context is unique, but because GLM-5.2's 1M context is solid and lossless.
Most models that advertise extended context windows suffer from two critical failure modes:
Needle-in-a-haystack degradation - retrieval accuracy collapses in the middle of long contexts
Attention drift - the model loses track of earlier instructions, constraints, or architectural decisions as more tokens are added
GLM-5.2 specifically addresses both. It has undergone months of specialized training across high-value long-horizon scenarios including:
Large-scale implementation tasks - implementing complete systems from specifications spanning thousands of lines
Automated research workflows - reading, synthesizing, and acting on extensive research corpora
Performance optimization - analyzing large codebases to identify bottlenecks and implement improvements
The practical result: GLM-5.2 can load an entire medium-to-large software repository - including backend services, frontend code, configuration files, tests, and documentation - into a single context window and maintain coherent, constraint-respecting output across a full development session.
Context window comparison:
Model | Context Window |
|---|---|
GLM-5.2 | 1,000,000 tokens |
GLM-5.1 | 200,000 tokens |
Claude Opus 4.8 | 200,000 tokens |
GPT-5.5 | 128,000 tokens |
Gemini 3.1 Pro | 1,000,000 tokens |
DeepSeek V4 Pro | 128,000 tokens |
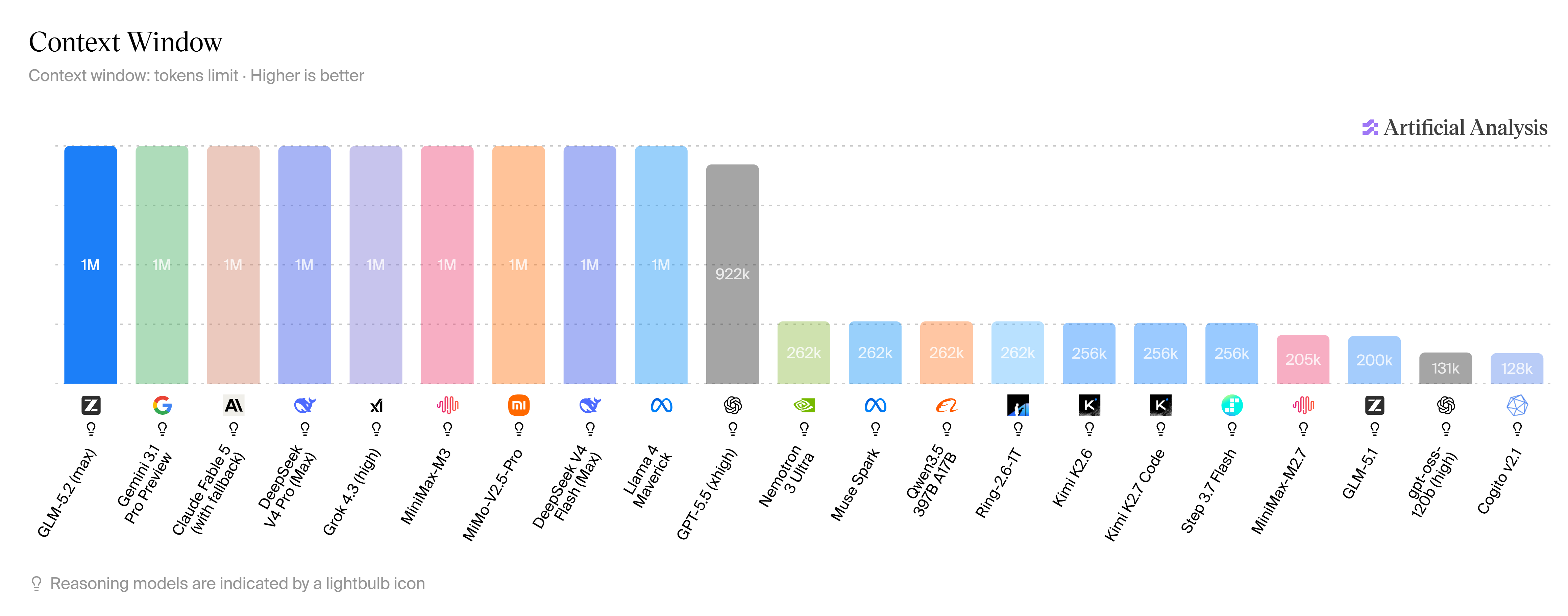
GLM-5.2's 5× context window expansion over GLM-5.1 (200K → 1M) is not just a number - it's what enables the long-horizon performance gains seen across FrontierSWE, PostTrainBench, and SWE-Marathon.
Capabilities at a Glance
GLM-5.2 ships with a complete suite of production-ready capabilities accessible via the API:
Thinking Mode
GLM-5.2 supports selectable thinking modes. You can enable or disable explicit chain-of-thought reasoning depending on your latency and quality requirements. When thinking is enabled, the model externalizes its reasoning process in a reasoning_content field separate from the final answer content.
Streaming Output
Full server-sent events (SSE) streaming is supported for real-time response delivery. Streaming works seamlessly with thinking mode - reasoning tokens and content tokens stream independently.
Function Calling (Tool Use)
GLM-5.2 has strong tool invocation capabilities, enabling integration with external APIs, databases, and services. Tool calls are structured and reliable - validated on benchmarks like MCP-Atlas (76.8) where it outperforms GPT-5.5.
Context Caching
An intelligent caching mechanism reduces latency and cost for long conversations and repeated prefixes. Cached tokens are priced at $0.275/M on Qubrid AI - a significant saving in document-heavy or system-prompt-heavy deployments.
Structured Output
GLM-5.2 supports constrained generation for JSON and other structured formats. This is particularly useful for agentic pipelines where downstream systems need predictable output schemas.
MCP (Model Context Protocol)
Native MCP support allows GLM-5.2 to flexibly integrate external tools and data sources, expanding application scenarios without bespoke tool-wrapping code.
Mobile Engineering Support
GLM-5.2 has specialized capability for Android and mobile development, including native integration with ADB, logcat, screenshots, and runtime logs. It can complete the full loop of code implementation → build → install → on-device verification.
Thinking Modes & Reasoning Effort Control
One of GLM-5.2's most practically useful features is explicit reasoning effort control via the reasoning_effort parameter. This lets you balance capability against speed and cost:
Mode |
| Best for |
|---|---|---|
Maximum reasoning |
| Complex multi-step tasks, SWE agent runs, hard math |
Default balanced |
| General-purpose coding, Q&A, moderate tasks |
Minimal reasoning |
| Fast turnaround, simple completions, cost sensitivity |
The enable_thinking object controls whether the model externalizes its reasoning:
extra_body={
"enable_thinking": True,``` // or "False"
"reasoning_effort": "max", // or "medium", "low"
}When enable_thinking is "true", streaming responses expose two token streams:
reasoning_content- the model's chain-of-thought tokenscontent- the final answer tokens
This separation allows you to display live thinking to users or suppress it for cleaner UI experiences.
At comparable token budgets, GLM-5.2 with reasoning_effort: "max" delivers substantially stronger agentic coding than GLM-5.1, with capability positioned between Claude Opus 4.7 and Claude Opus 4.8.
Benchmark Deep Dive
This section covers every confirmed benchmark score for GLM-5.2 with comparisons to GPT-5.5, Claude Opus 4.7, Claude Opus 4.8, Gemini 3.1 Pro, and GLM-5.1.
Long-Horizon Coding Benchmarks
These are the benchmarks that best capture GLM-5.2's core differentiating capability.
FrontierSWE
FrontierSWE measures an agent's ability to complete open-ended technical projects at the scale of hours to tens of hours, spanning systems optimization, large-scale code construction, and applied ML research. These are multi-session tasks that go well beyond simple bug fixing.
Model | FrontierSWE Score |
|---|---|
Claude Opus 4.8 | 75.1% |
GLM-5.2 | 74.4% |
GPT-5.5 | 72.6% |
Claude Opus 4.7 | ~63% |
GLM-5.2 trails Opus 4.8 by just 0.7 percentage points on FrontierSWE - an extraordinary result for an open-weights model - while decisively outperforming GPT-5.5 by 1.8 points and Opus 4.7 by approximately 11 points.
PostTrainBench
PostTrainBench evaluates whether an agent, given an H100 GPU, can meaningfully improve a smaller model through post-training (fine-tuning, RLHF, DPO, etc.). This is a highly specialized capability that tests both ML research understanding and autonomous tool use.
Model | PostTrainBench Score |
|---|---|
Claude Opus 4.8 | ~40% |
GLM-5.2 | 34.3% |
GPT-5.5 | ~28% |
Claude Opus 4.7 | ~27% |
GLM-5.2 outperforms both GPT-5.5 and Claude Opus 4.7 on PostTrainBench, trailing only Opus 4.8 - remarkable given the model's open-weights status.
SWE-Marathon
SWE-Marathon is the most demanding long-horizon software engineering benchmark, covering ultra-long tasks such as building compilers, optimizing CUDA kernels, and developing production-grade services from scratch.
Model | SWE-Marathon Score |
|---|---|
Claude Opus 4.8 | 26.0% |
GLM-5.2 | 13.0% |
Gemini 3.1 Pro | 4.0% |
GLM-5.2 lags Opus 4.8 by 13 percentage points on SWE-Marathon - the benchmark where the closed-source frontier pulls furthest ahead - but still decisively leads the rest of the open-source field, with Gemini 3.1 Pro scoring only 4.0%.
Standard Coding Benchmarks
Terminal-Bench 2.1
Terminal-Bench tests an agent's ability to autonomously operate in a terminal environment - running commands, reading outputs, iterating on errors, and completing tasks without a human in the loop.
Model | Terminal-Bench 2.1 Score |
|---|---|
Claude Opus 4.8 | 85.0 |
GLM-5.2 | 81.0 |
Gemini 3.1 Pro | <80.0 |
GLM-5.1 | 63.5 |
GLM-5.2 is the first open-weights model to break 80% on Terminal-Bench 2.1, a milestone noted by Cline IDE at launch. The improvement over GLM-5.1 (63.5 → 81.0, +17.5 points) is exceptional.
SWE-bench Pro
SWE-bench Pro tests whether models can resolve real-world GitHub issues from popular open-source repositories - the gold standard for practical software engineering capability.
Model | SWE-bench Pro Score |
|---|---|
Claude Opus 4.8 | 69.2 |
GLM-5.2 | 62.1 |
GPT-5.5 | 58.6 |
GLM-5.1 | 58.4 |
GLM-5.2 scores 62.1 on SWE-bench Pro, ahead of both GPT-5.5 (58.6) and GLM-5.1 (58.4), while trailing Opus 4.8 (69.2).
NL2Repo
NL2Repo evaluates the ability to create and populate an entire repository from natural language specifications.
Model | NL2Repo Score |
|---|---|
Claude Opus 4.8 | 69.7 |
GLM-5.2 | 48.9 |
GPT-5.5 | ~45% |
NL2Repo is one of the benchmarks where the gap to Opus 4.8 is more pronounced (~21 points), suggesting that ultra-long project creation from scratch remains a frontier-class capability.
Math & Scientific Reasoning
AIME 2026 (Math Competition)
Model | AIME 2026 Score |
|---|---|
GLM-5.2 | 99.2 |
GLM-5.2 achieves 99.2 on AIME 2026, placing it among the top mathematical reasoners available.
GPQA Diamond
GPQA Diamond is a graduate-level science Q&A benchmark designed to be difficult for non-expert humans but tractable for frontier models.
Model | GPQA Diamond |
|---|---|
GLM-5.2 | 89% |
GLM-5.1 | 86% |
GLM-5.2 gains 3 points over GLM-5.1 on GPQA Diamond.
Humanity's Last Exam (HLE) with Tools
HLE is one of the hardest reasoning benchmarks, covering obscure expert-level knowledge across many domains.
Model | HLE with Tools |
|---|---|
Claude Opus 4.8 | 57.9 |
GLM-5.2 | 54.7 |
GPT-5.5 | 52.2 |
GLM-5.2 outperforms GPT-5.5 by 2.5 points on HLE with Tools, trailing Opus 4.8 by 3.2 points.
CritPt (Critical Point / Scientific Reasoning)
Per Artificial Analysis benchmarking, GLM-5.2 gains +16 points over GLM-5.1 on CritPt (to 21%) - one of the largest improvements in the benchmark suite.
HLE (Standalone, no tools)
GLM-5.2 gains +12 points over GLM-5.1 (to 40%) on standalone HLE.
SciCode
SciCode evaluates the ability to solve complex scientific programming tasks. GLM-5.2 achieves 50%, a +7 point improvement over GLM-5.1.
Agentic & Tool Use Benchmarks
MCP-Atlas
MCP-Atlas specifically tests an agent's tool invocation accuracy and reliability - critical for production agentic systems.
Model | MCP-Atlas Score |
|---|---|
Claude Opus 4.8 | 77.8 |
GLM-5.2 | 76.8 |
GPT-5.5 | 75.3 |
GLM-5.2 outperforms GPT-5.5 on MCP-Atlas and sits within 1 point of Claude Opus 4.8.
AA-LCR (Long-Context Retrieval)
Artificial Analysis Long-Context Retrieval evaluates information retrieval and coherence over long contexts - directly relevant to the 1M token context window claim.
GLM-5.2: 71% (+9 points over GLM-5.1)
tau3 Banking (Agentic Finance)
GLM-5.2: 27% (+15 points over GLM-5.1)
TerminalBench v2.1 (AA evaluation)
GLM-5.2: 78% (+16 points over GLM-5.1)
Artificial Analysis Intelligence Index
The Artificial Analysis Intelligence Index v4.1 is one of the most rigorous independent multi-task LLM evaluations, aggregating performance across reasoning, coding, knowledge, math, and agentic tasks with a particular emphasis on real-world workloads.
Model | Intelligence Index v4.1 Score |
|---|---|
Claude Fable 5 | ~56 |
GLM-5.2 | 51 |
MiniMax-M3 | 44 |
DeepSeek V4 Pro (max) | 44 |
Kimi K2.6 | 43 |
GLM-5.1 | 40 |
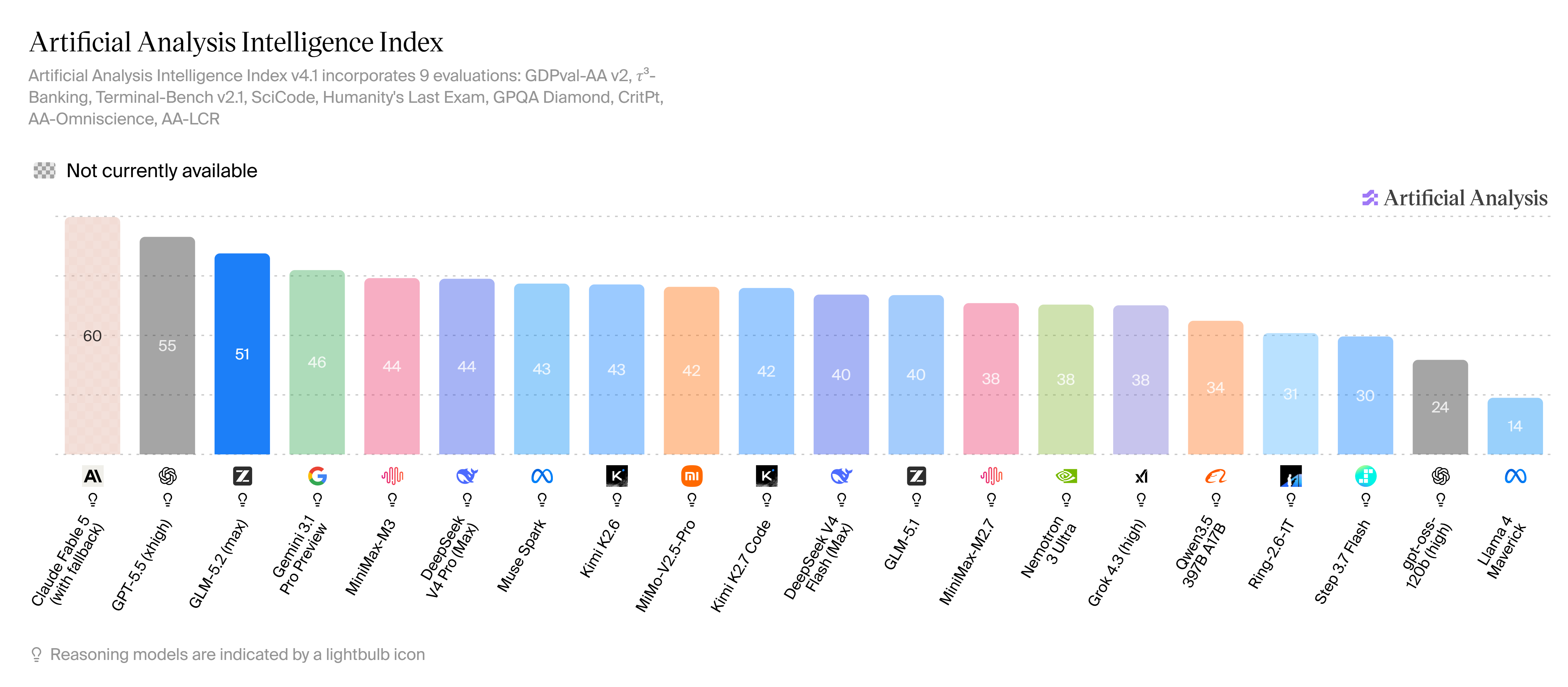
GLM-5.2 scores 51 - an 11-point improvement over GLM-5.1 (40) - and leads all open-weights models by a 7-point margin. It is the highest-scoring open-weights model on the Intelligence Index v4.1, positioned just 5 points below Claude Fable 5.
Key Intelligence Index sub-metric improvements (GLM-5.2 vs. GLM-5.1):
Benchmark | GLM-5.1 | GLM-5.2 | Gain |
|---|---|---|---|
CritPt | 5% | 21% | +16 pts |
HLE | 28% | 40% | +12 pts |
tau3 Banking | 12% | 27% | +15 pts |
AA-LCR | 62% | 71% | +9 pts |
SciCode | 43% | 50% | +7 pts |
TerminalBench v2.1 | 62% | 78% | +16 pts |
GPQA Diamond | 86% | 89% | +3 pts |
GDPval-AA v2: Real-World Agentic Performance
GDPval-AA v2 is Artificial Analysis's primary metric for real-world agentic performance. It baselines Elo to human performance at 1000, uses a rotating panel of frontier-model judges, and allows up to 250 turns per trajectory - specifically designed to capture long-horizon agentic capability.
Model | GDPval-AA v2 Score |
|---|---|
Claude Fable 5 | ~1600 |
GLM-5.2 | 1524 |
GPT-5.5 (xhigh reasoning) | 1514 |
MiniMax-M3 | 1418 |
DeepSeek V4 Pro (max) | 1328 |
GLM-5.2 scores 1524 on GDPval-AA v2, placing it effectively level with GPT-5.5 (xhigh, 1514) - and 106 points ahead of MiniMax-M3. This is the benchmark result that most dramatically demonstrates GLM-5.2's real-world agentic capability relative to its price point.
GLM-5.2 leads all open-weights models on GDPval-AA v2.
AA-Omniscience Index
The AA-Omniscience Index evaluates knowledge, hallucination rate, and attempt rate.
Metric | GLM-5.1 | GLM-5.2 |
|---|---|---|
AA-Omniscience Score | 2 | 4 |
Accuracy | 24.2% | 25.1% |
Hallucination Rate | 29.4% | 28.1% |
Attempt Rate | 47% | 47% (flat) |
GLM-5.2 improves on GLM-5.1 on both accuracy and hallucination rate, while maintaining the same attempt rate.
Full Benchmark Comparison Table
Benchmark | GLM-5.2 | Claude Opus 4.8 | GPT-5.5 | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|---|---|---|
AI Intelligence Index v4.1 | 51 | ~56 | ~50 | ~44 | 40 |
GDPval-AA v2 | 1524 | - | 1514 | - | - |
FrontierSWE | 74.4% | 75.1% | 72.6% | ~63% | - |
Terminal-Bench 2.1 | 81.0 | 85.0 | - | - | 63.5 |
SWE-bench Pro | 62.1 | 69.2 | 58.6 | - | 58.4 |
PostTrainBench | 34.3% | ~40% | ~28% | ~27% | - |
SWE-Marathon | 13.0% | 26.0% | - | - | - |
MCP-Atlas | 76.8 | 77.8 | 75.3 | - | - |
HLE with Tools | 54.7 | 57.9 | 52.2 | - | - |
AIME 2026 | 99.2 | - | - | - | - |
GPQA Diamond | 89% | - | - | - | 86% |
SciCode | 50% | - | - | - | 43% |
AA-LCR | 71% | - | - | - | 62% |
HLE (standalone) | 40% | - | - | - | 28% |
NL2Repo | 48.9 | 69.7 | ~45% | - | - |
GLM-5.2 vs. The Competition
GLM-5.2 vs. Claude Opus 4.8
Claude Opus 4.8 is the current closed-source frontier for coding and agentic tasks. The honest comparison:
GLM-5.2 wins / ties:
FrontierSWE: 74.4% vs 75.1% (near-tie, within 1%)
MCP-Atlas: 76.8 vs 77.8 (near-tie, within 1%)
Code Arena Frontend: GLM-5.2 ranked #2, above Opus 4.8 in thinking mode
Context Window: 1M vs 200K (5× larger)
Cost: ~6× cheaper per token
License: MIT open-weights vs. closed-source
Opus 4.8 wins:
SWE-bench Pro: 69.2 vs 62.1 (−7.1 points)
SWE-Marathon: 26.0% vs 13.0% (−13 points)
NL2Repo: 69.7 vs 48.9 (−20.8 points)
Terminal-Bench 2.1: 85.0 vs 81.0 (−4 points)
HLE with Tools: 57.9 vs 54.7 (−3.2 points)
Verdict: For mainstream and frontend coding tasks, GLM-5.2 is effectively at parity with Opus 4.8 at a fraction of the cost. The gap widens meaningfully only on the hardest ultra-long-horizon tasks.
GLM-5.2 vs. GPT-5.5
GLM-5.2 wins across the board:
FrontierSWE: 74.4% vs 72.6% (+1.8%)
SWE-bench Pro: 62.1 vs 58.6 (+3.5)
PostTrainBench: 34.3% vs ~28% (+6+ pts)
MCP-Atlas: 76.8 vs 75.3 (+1.5)
HLE with Tools: 54.7 vs 52.2 (+2.5)
GDPval-AA v2: 1524 vs 1514 (+10)
Cost: ~6× cheaper
License: MIT open-weights vs. closed-source
Context: 1M vs 128K
Verdict: GLM-5.2 is a clear winner over GPT-5.5 on coding and agentic tasks at dramatically lower cost.
GLM-5.2 vs. DeepSeek V4 Pro
GLM-5.2 wins:
Intelligence Index: 51 vs 44 (+7)
GDPval-AA v2: 1524 vs 1328 (+196)
Context Window: 1M vs 128K
DeepSeek V4 Pro wins:
Cost per task: $0.05 vs $0.46 (~9× cheaper on first-party API)
Verdict: GLM-5.2 is substantially more capable but more expensive. DeepSeek V4 Pro remains the best option for cost-sensitive, high-volume workloads.
GLM-5.2 vs. MiniMax-M3
Intelligence Index: 51 vs 44 (+7)
GDPval-AA v2: 1524 vs 1418 (+106)
Output tokens per task: 43K vs 24K (GLM-5.2 uses more)
Cost per task on first-party API: $0.46 vs $0.18
Verdict: GLM-5.2 is significantly more capable but at higher per-task cost due to its heavier use of output/reasoning tokens.
Key Use Cases
1. Long-Horizon Software Engineering Agents
GLM-5.2 is the leading open-weights model for agentic coding frameworks like Cline, Kilo Code, Cursor, and Windsurf. Its 1M context window means an entire repository can be loaded and referenced consistently across a multi-step task.
Example prompt:
Please read the current project and produce a system architecture map, core module
responsibilities, key interface contracts, main data flows, potential risk points,
and the engineering constraints that must be followed during subsequent refactoring.2. Mobile & Android Development (ADB Loop)
GLM-5.2 has native understanding of Android engineering workflows:
Example prompt:
Please implement a native Android client in Kotlin that integrates with the
existing server-side API, supporting multi-session, streaming messages, voice input,
notifications, and reconnection on disconnect. After completion, install it on a
real device using ADB, and complete debugging with logcat and screenshots.3. Cross-Module Root Cause Analysis & Debugging
For complex bugs spanning multiple services, configuration, and call chains:
Example prompt:
Please trace the root cause of the problem along the call chain, explaining which
modules, configurations, interfaces, or data flows are involved. Determine whether
there are similar risks, and provide a minimal fix plan, verification steps, and
a regression checklist.4. Production-Grade Standards-Adherent Development
For teams with strict coding standards, GLM-5.2 can be instructed to adhere to style guides, lint rules, build commands, and commit constraints:
Example prompt:
Please strictly follow the current repository's engineering standards. Do not
introduce new dependencies, do not modify interface contracts, and do not
proactively commit. After the modification is complete, run the build, lint,
and tests, and explain the verification results and any uncovered risks.5. Post-Training & ML Research Automation
GLM-5.2's strong PostTrainBench score makes it well-suited for ML automation workflows: hyperparameter search, training pipeline orchestration, and evaluating model checkpoints.
6. Large Document Analysis & Long-Context RAG
With 1M tokens of usable context, GLM-5.2 can process entire codebases, legal documents, research papers, or knowledge bases in a single prompt - eliminating chunking errors common in traditional RAG pipelines.
API Reference & Integration Guide
GLM-5.2 on Qubrid AI uses an OpenAI-compatible API interface, making migration from other providers trivial.
Endpoint
https://platform.qubrid.com/v1Authentication
Authorization: Bearer YOUR_QUBRID_API_KEYBasic Request (cURL)
curl -X POST "https://platform.qubrid.com/v1/chat/completions" \
-H "Authorization: Bearer QUBRID_API_KEY" \
-H "Content-Type: application/json" \
-d '{
// Must match the exact model ID from the docs — variations will cause errors.
"model": "zai-org/GLM-5.2",
"messages": [
{
"role": "user",
"content": "Explain the main benefits of using a chat completion API for text generation."
}
],
"temperature": 1,
"max_tokens": 4096,
"stream": false,
"top_p": 1,
"enable_thinking": true,
"reasoning_effort": "max"
}'Streaming Request (cURL)
curl -X POST "https://platform.qubrid.com/v1/chat/completions" \
-H "Authorization: Bearer QUBRID_API_KEY" \
-H "Content-Type: application/json" \
-d '{
// Must match the exact model ID from the docs — variations will cause errors.
"model": "zai-org/GLM-5.2",
"messages": [
{
"role": "user",
"content": "Explain the main benefits of using a chat completion API for text generation."
}
],
"temperature": 1,
"max_tokens": 4096,
"stream": true,
"top_p": 1,
"enable_thinking": true,
"reasoning_effort": "max"
}'JavaScript/TypeScript Example
import OpenAI from 'openai';
const client = new OpenAI({
baseURL: 'https://platform.qubrid.com/v1',
apiKey: 'QUBRID_API_KEY',
});
const stream = await client.chat.completions.create({
// Must match the exact model ID from the docs — variations will cause errors.
model: 'zai-org/GLM-5.2',
messages: [
{
"role": "user",
"content": "Explain the main benefits of using a chat completion API for text generation."
}
],
max_tokens: 4096,
temperature: 1,
top_p: 1,
stream: true,
enable_thinking: true,
reasoning_effort: 'max'
});
for await (const chunk of stream) {
if (chunk.choices[0]?.delta?.content) {
process.stdout.write(chunk.choices[0].delta.content);
}
}
console.log('\n');Key API Parameters
Parameter | Type | Description |
|---|---|---|
| string |
|
| array | Conversation history in OpenAI format |
| string |
|
| string |
|
| boolean |
|
| integer | Maximum output tokens (up to 128,000) |
| float | Sampling temperature (0.0–2.0; 1.0 recommended for reasoning) |
Pricing on Qubrid AI
Qubrid AI offers GLM-5.2 at competitive, transparent per-token pricing with no hidden fees:
Token Type | Price per 1M Tokens |
|---|---|
Input tokens | $1.10 |
Cached input tokens | $0.275 |
Output tokens | $3.851 |
Cost Analysis
Context caching (at $0.275/M) delivers a ~5× discount on cached input tokens, making repeated long-system-prompt workloads highly economical.
Cost per task estimate (based on Artificial Analysis methodology, ~43K output tokens per Intelligence Index task):
Approximate cost per complex task on Qubrid AI: ~$0.50–$0.55
Comparison to closed-source alternatives:
Model | Input ($/M) | Output ($/M) | Relative Cost |
|---|---|---|---|
GLM-5.2 (Qubrid AI) | $1.10 | $3.851 | 1× |
GPT-5.5 | ~$10.00 | ~$30.00 | ~6× more expensive |
Claude Opus 4.8 | ~$15.00 | ~$75.00 | ~10–14× more expensive |
GLM-5.2 on Qubrid AI delivers near-frontier agentic coding capability at a fraction of the cost of equivalent closed-source models - making it the most cost-efficient choice for:
High-volume agentic pipelines
Development teams with multiple concurrent agents
Organizations evaluating AI coding assistants at scale
Startups building AI-native products
Open Weights & MIT License
GLM-5.2 is released under the MIT license - the most permissive open-source license available. This means:
Self-hosting - deploy on your own infrastructure for maximum data control
Commercial use - no restrictions on commercial deployment
Modification - fine-tune, quantize, or adapt the model for your specific use case
Distribution - redistribute the model weights freely
No vendor lock-in - your application is not tied to any single API provider
The open weights are available on Hugging Face from the zai-org organization. This provides an important fallback: even if you use Qubrid AI's API for production convenience, you can always switch to self-hosted inference if your compliance or latency requirements demand it.
For teams with data residency requirements or regulatory constraints, the MIT license means GLM-5.2 is one of the few frontier-adjacent models that can be deployed entirely within your own infrastructure.
Token Efficiency & Cost-Per-Task Analysis
GLM-5.2's Achilles' heel in pure cost-efficiency terms is its token usage. Per Artificial Analysis measurements, the model uses an average of 43,000 output tokens per Intelligence Index task, of which approximately 37,000 tokens are reasoning tokens.
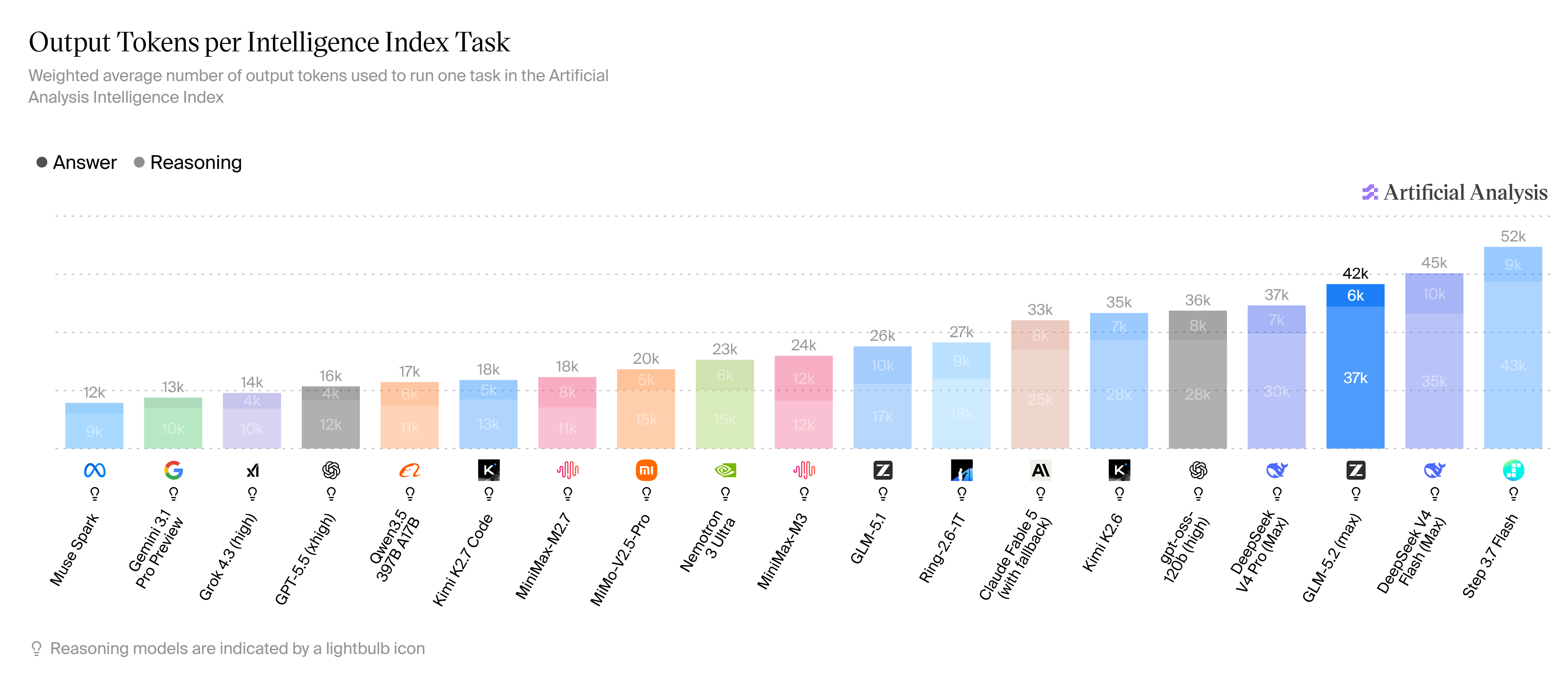
For comparison:
Model | Output Tokens / Task | Reasoning Tokens / Task |
|---|---|---|
GLM-5.2 | 42K | ~37K |
Kimi K2.6 | 35K | - |
DeepSeek V4 Pro (max) | 37K | - |
MiniMax-M3 | 24K | - |
GLM-5.1 | 26K | - |
GLM-5.2 is among the heavier token consumers at its intelligence level - a direct consequence of its reasoning_effort: max default and extensive chain-of-thought generation. This is a deliberate tradeoff: more reasoning tokens correlate with higher accuracy on complex tasks.
Practical guidance:
For simple completions or cost-sensitive high-volume workloads, use
reasoning_effort: "low"or"medium"andthinking: "disabled"Reserve
reasoning_effort: "max"for complex agentic tasks where quality is paramountUse context caching ($0.275/M) aggressively for long system prompts and repeated context
GLM-5.2 vs. GLM-5.1: What Changed
GLM-5.2 and GLM-5.1 share the same architecture (744B total / 40B active MoE), but GLM-5.2 represents a major training advancement:
Dimension | GLM-5.1 | GLM-5.2 | Change |
|---|---|---|---|
Context Window | 200K tokens | 1M tokens | 5× increase |
Intelligence Index | 40 | 51 | +11 points |
Terminal-Bench 2.1 | 63.5 | 81.0 | +17.5 points |
SWE-bench Pro | 58.4 | 62.1 | +3.7 points |
GPQA Diamond | 86% | 89% | +3 points |
SciCode | 43% | 50% | +7 points |
HLE (standalone) | 28% | 40% | +12 points |
CritPt | 5% | 21% | +16 points |
tau3 Banking | 12% | 27% | +15 points |
AA-LCR | 62% | 71% | +9 points |
AA-Omniscience Score | 2 | 4 | +2 |
Hallucination Rate | 29.4% | 28.1% | Improved |
Max Output Tokens | 64K | 128K | 2× increase |
Effort Control | ❌ | ✅ | New feature |
Output tokens/task | 26K | 43K | +17K (heavier reasoning) |
The scale of improvement across every benchmark is what has led independent evaluators to describe GLM-5.2 as a qualitatively different model rather than an incremental update.
Frequently Asked Questions
Q: What is GLM-5.2?
A: GLM-5.2 is Z.ai (Zhipu AI)'s flagship open-weights large language model, released June 2026. It is a 744B-parameter Mixture-of-Experts model with 40B active parameters, a 1M-token context window, and MIT license. It is currently the leading open-weights model on the Artificial Analysis Intelligence Index v4.1.
Q: What is GLM-5.2's API endpoint?
A: On Qubrid AI, access GLM-5.2 via https://platform.qubrid.com/v1/chat/completions with model string "zai-org/GLM-5.2". The API is fully OpenAI-compatible.
Q: What are the GLM-5.2 benchmark scores?
A: Key scores include: Terminal-Bench 2.1 (81.0), SWE-bench Pro (62.1), FrontierSWE (74.4%), MCP-Atlas (76.8), HLE with Tools (54.7), AIME 2026 (99.2), GPQA Diamond (89%), Intelligence Index v4.1 (51), GDPval-AA v2 (1524).
Q: What is GLM-5.2 pricing on Qubrid AI?
A: Input: $1.10/M tokens | Cached: $0.275/M tokens | Output: $3.851/M tokens.
Q: How does GLM-5.2 compare to Claude Opus 4.8?
A: GLM-5.2 is within 1% of Opus 4.8 on FrontierSWE and effectively tied on MCP-Atlas. It trails Opus 4.8 on SWE-bench Pro (62.1 vs 69.2) and SWE-Marathon (13% vs 26%). It is approximately 6–14× cheaper and has a 5× larger context window (1M vs 200K). It is fully open-source under MIT license; Opus 4.8 is closed-source.
Q: How does GLM-5.2 compare to GPT-5.5?
A: GLM-5.2 outperforms GPT-5.5 across most key benchmarks: FrontierSWE (+1.8%), SWE-bench Pro (+3.5 points), PostTrainBench (+6+ pts), MCP-Atlas (+1.5), HLE with Tools (+2.5), GDPval-AA v2 (+10 Elo points). It is also ~6× cheaper and carries an MIT open-source license.
Q: Is GLM-5.2 open source?
A: Yes. GLM-5.2 is released under the MIT license. Open weights are available on Hugging Face under the zai-org organization.
Q: What is the GLM-5.2 context window?
A: 1,000,000 tokens (1M). This is a 5× expansion over GLM-5.1's 200K context window and is specifically optimized for long-horizon tasks, not just nominally extended.
Q: What is GLM-5.2's maximum output length?
A: 128,000 tokens (128K).
Q: What is GLM-5.2 Thinking Mode?
A: Thinking Mode enables the model to externalize its chain-of-thought reasoning in a reasoning_content field. It can be enabled or disabled per request. Combined with reasoning_effort control ("low", "medium", "max"), it allows fine-grained tradeoffs between speed, cost, and answer quality.
Q: Is GLM-5.2 available for self-hosting?
A: Yes. The MIT license and publicly available weights on Hugging Face allow full self-hosting. For managed API access with Day 0 availability and competitive pricing, use Qubrid AI.
Q: What IDEs and coding tools support GLM-5.2?
A: Cline, Kilo Code, Cursor, and Windsurf confirmed Day 0 integration. As an OpenAI-compatible API, any tool that supports custom model endpoints works with GLM-5.2 on Qubrid AI.
Q: What is the difference between GLM-5.2 and GLM-5.1?
A: Same architecture (744B/40B MoE), but GLM-5.2 has a 1M context window (vs 200K), 11 more points on the Intelligence Index (51 vs 40), and major benchmark improvements across coding, math, and scientific reasoning, plus new effort-level control. See the comparison table above.
Get Started with GLM-5.2 on Qubrid AI
GLM-5.2 is available today on Qubrid AI - no waitlist, no restrictions, with full Day 0 feature support.
Access GLM-5.2 via the Qubrid AI API:
from openai import OpenAI
# Initialize the OpenAI client with Qubrid base URL
client = OpenAI(
base_url="https://platform.qubrid.com/v1",
api_key="QUBRID_API_KEY",
)
stream = client.chat.completions.create(
# Must match the exact model ID from the docs — variations will cause errors.
model="zai-org/GLM-5.2",
messages=[
{
"role": "user",
"content": "Explain the main benefits of using a chat completion API for text generation."
}
],
max_tokens=4096,
temperature=1,
top_p=1,
stream=True,
extra_body={
"enable_thinking": True,
"reasoning_effort": "max",
}
)
for chunk in stream:
if chunk.choices and chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
print("\n")Pricing recap:
Input: $1.10 / 1M tokens
Cached Input: $0.275 / 1M tokens
Output: $3.851 / 1M tokens
Try the model today: https://platform.qubrid.com/model/glm-5.2
