Managed AI Inference & GPU Infrastructure Hosting
Your GPUs. We run everything else.
A dedicated NVIDIA GPU cluster, procured, deployed, and operated by Qubrid. You own the hardware—we handle hosting, operations, and the full AI software stack.
- Dedicated rack hosting with up to 17KW+ per rack power. Your hardware, our facility.
- Full NVIDIA stack management: drivers, CUDA, NCCL, Fabric Manager, firmware
- End-to-end vendor coordination so you never deal with OEMs directly
- AI platform support: model deployment, inference, fine-tuning, and RAG pipelines
- Per rack power
- 17KW+
- Per rack power
- dedicated capacity
- 100%
- dedicated capacity
- operations & monitoring
- 24/7
- operations & monitoring
- internal ops overhead
- Zero
- internal ops overhead

NVIDIA Certified
Data Center Facility

Tier
III+
Compliance
SOC Type 2
Security
24/7

Our partnership with NVIDIA enables us to deliver enterprise-grade GPU infrastructure hosting, full NVIDIA stack management, and AI platform support for customer-owned systems. NVIDIA Certified Data Centers are available in our network. Not all facilities are certified.
Enterprise AI infrastructure, fully managed and customer-owned
- 17KW+Per rack power
- Enterprisegrade hosting
- NVIDIAAI stack expertise
- End-to-endoperations
- AI Platformsupport
- 24/7monitoring
Four steps to production-ready GPU infrastructure
From initial architecture to a fully operational NVIDIA GPU cluster, with no internal infrastructure headcount required.
- 01Design
Architecture & cluster design
We architect the cluster for your workload: server density, InfiniBand topology, rack layout, power allocation, and facility requirements.
- 02Procure
Hardware procurement & coordination
Qubrid coordinates directly with Supermicro, Dell, HPE, and NVIDIA. OEM pricing and delivery timelines without the procurement overhead.
- 03Deploy
Rack, stack & production commissioning
Receiving, inspection, rack mounting, structured cabling, network integration, burn-in testing, and production handoff to your team.
- 04Operate
24/7 managed operations
Continuous monitoring, firmware and OS management, performance optimization, incident response, and OEM break-fix coordination.
Managed AI Infrastructure Without the Operational Complexity
Qubrid provides a complete managed hosting and operations solution for organizations that want to own their AI infrastructure without building internal infra teams.
What this service is
Own your AI infrastructure without operating it yourself. Qubrid manages every operational layer, from facility hosting to software stack maintenance, so your teams can focus on building and deploying AI workloads.
“Own your AI infrastructure without operating it yourself.”
- 01
You own the hardware
Purchase and retain full ownership of your GPU systems. CapEx on your balance sheet, with residual value at end of contract. Qubrid never resells your infrastructure.
- 02
Qubrid operates everything
Facility hosting, networking, security, 24/7 monitoring, firmware management, and day-to-day operations, all under a single managed service agreement.
- 03
Zero internal ops overhead
No need to hire infrastructure engineers, negotiate with OEMs, or manage data center relationships. Qubrid is your single point of contact.
- 04
Focus on AI, not infrastructure
Your teams build models, deploy inference, and ship products. We handle rack-and-stack, burn-in, software stack management, and vendor coordination.
Infrastructure Hosting & Data Center Services
Enterprise-grade facility services for customer-owned GPU systems, from dedicated rack space to continuous environmental monitoring.
Facility
Tier III+ Colocation
Enterprise hosting
GPU-Ready Data Center
Power
17KW+
Per rack power
Uptime
99.97%
SLA
Cooling
N+1
redundant
- 01
Dedicated rack space
Secure, dedicated rack allocation for customer-owned GPU systems in enterprise-grade facilities.
- 02
Up to 17KW+ per rack power
High-density power allocation supporting the latest NVIDIA GPU clusters and multi-node configurations.
- 03
Redundant power distribution
Dual-path power delivery with UPS and generator backup for continuous uptime.
- 04
Environmental controls
Precision cooling, humidity management, and thermal monitoring for optimal GPU performance.
- 05
High-speed networking
Low-latency interconnects, high-bandwidth uplinks, and optimized east-west traffic for AI workloads.
- 06
Firewall & network security
Perimeter firewalls, network segmentation, and traffic inspection for enterprise security posture.
- 07
Physical security & access
Biometric access controls, 24/7 surveillance, and strict facility entry protocols.
- 08
Remote hands support
On-site technicians for physical tasks including cable management, drive swaps, and hardware inspections.
- 09
Continuous facility monitoring
Real-time environmental and facility health monitoring with automated alerting.
Your infrastructure never sleeps. Neither do we.
Real-time monitoring across every GPU, node, and network path, with proactive maintenance, performance optimization, and rapid incident response built in.
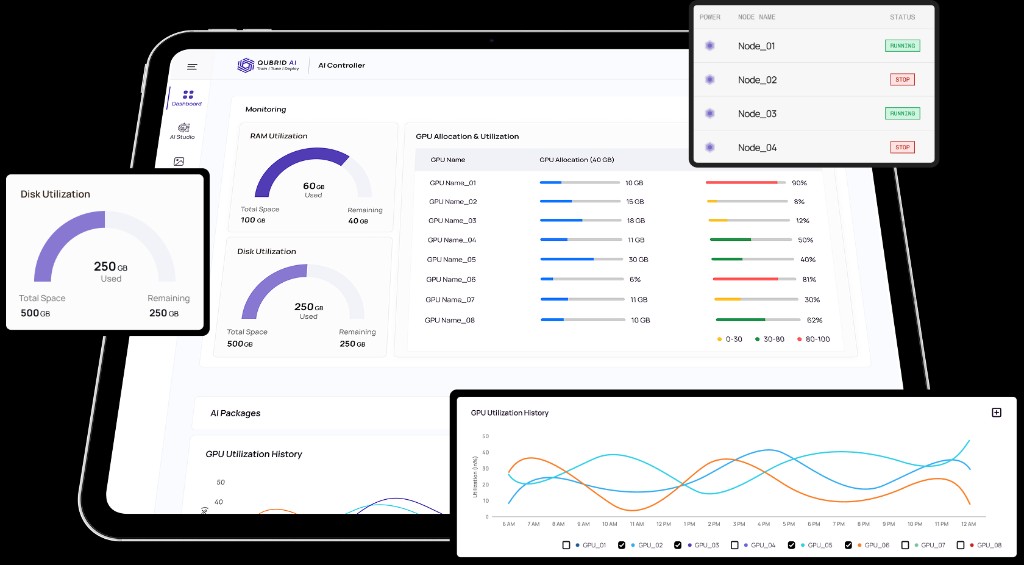
Live monitoring coverage
- GPU utilization
- CPU utilization
- Memory consumption
- Storage I/O
- Network performance
- GPU thermals
- Power consumption
- System health
- Hardware alerts
- Interconnect health
Operational activities
- 01
Capacity reviews
Regular analysis of utilization trends to inform scaling and procurement decisions.
- 02
Performance optimization
Tuning GPU configurations, network paths, and software settings for workload efficiency.
- 03
Preventative maintenance
Scheduled firmware updates, thermal checks, and hardware health assessments.
- 04
Incident response
24/7 on-call infrastructure team with defined escalation paths and SLA commitments.
AI Platform & Model Deployment Support
Qubrid goes beyond infrastructure. We help operationalize AI workloads on your dedicated GPU clusters.
- 01
Open-source model deployment
Deploy DeepSeek, Llama, Qwen, Mistral, Gemma, and other frontier models on your infrastructure.
- 02
LLM hosting & inference
Production-grade LLM serving with optimized batching, KV cache management, and autoscaling.
- 03
API deployment
OpenAI-compatible API endpoints deployed on your dedicated GPU clusters.
- 04
Multi-model environments
Run multiple models concurrently with intelligent GPU allocation and workload scheduling.
- 05
RAG & vector databases
End-to-end RAG pipeline deployment with vector database integration and retrieval optimization.
- 06
Benchmarking & scaling
Performance benchmarking, inference optimization, and horizontal scaling guidance.
Supported model families 
Deploy frontier open-source and commercial models on your dedicated GPU clusters.
Fine-Tuning & Model Customization Support
Leverage proprietary data without infrastructure complexity. Qubrid sets up and optimizes fine-tuning environments on your dedicated GPU clusters.
Training pipeline
From dataset preparation through multi-GPU training, evaluation, and production deployment, Qubrid runs the full fine-tuning lifecycle on your dedicated GPU clusters so your team can focus on model quality, not training infrastructure.
“Leverage proprietary data without building a training ops team.”
- 01
Fine-tuning environment setup
Pre-configured training environments with optimized data pipelines and GPU allocation.
- 02
Dataset preparation guidance
Best practices for data formatting, tokenization, and quality validation for training runs.
- 03
Hyperparameter recommendations
Infrastructure-aware tuning recommendations based on your GPU configuration and model size.
- 04
Training optimization
Multi-GPU training configuration, gradient checkpointing, and memory optimization strategies.
- 05
Post-training deployment
Seamless transition from fine-tuned checkpoints to production inference endpoints.
Unified AI Infrastructure Management Dashboard
One console for your entire GPU fleet: real-time visibility, workload management, and capacity planning. Currently in active development.
Qubrid AI Platform
Infrastructure Manager
Your clusters
Total GPUs
256
+32 planned
Active Workloads
18
3 training
Open Alerts
3
1 critical
Rack utilization
Planned features
- 01Real-time GPU monitoring
- 02Cluster health overview
- 03Utilization analytics
- 04Thermal monitoring
- 05Workload visibility
- 06User & project management
- 07Alerting & notifications
- 08Support ticket tracking
- 09Capacity planning
Different from ops console
The Infrastructure Manager is your fleet-level control plane for capacity planning, team access, alerts, and support tickets. The ops console handles real-time cluster monitoring.
Build AI, Not Infrastructure Operations
Tell us your GPU count and timeline. Our infrastructure team will architect your cluster, coordinate procurement, and deliver a production-ready environment, fully managed by Qubrid.