Qwen3.7-Plus Is Now Available on Qubrid AI
Most "multimodal" models follow a familiar pattern: add vision as an input modality, let the model describe what it sees, and call it done. The output is still text. The model is still passive. You still need a separate pipeline to turn the description into something executable.
Qwen3.7-Plus is built differently. Released by Alibaba's Qwen team on June 1, 2026, it is not a language model with vision attached - it is an agent model designed to close the loop between perception and execution. It perceives screens, reads interfaces, writes code from visual references, calls tools, runs tests, checks its own output, and iterates until the task is complete. It does this across both GUI and CLI environments, within a single context window, without switching models or pipelines. That is a fundamentally different architecture than vision-augmented text generation, and it changes what you can actually build.
Qwen3.7-Plus is available on Qubrid AI right now, with 20% off for early adopters. No waitlist, no separate API key provisioning, no friction. Access it at platform.qubrid.com/model/qwen3.7-plus.
What Qwen3.7-Plus Actually Is
The Qwen3.7 family launched in May 2026 with two models designed for different use cases. Qwen3.7-Max is the text-only flagship, tuned for long-horizon agentic coding and reasoning. Qwen3.7-Plus is its multimodal sibling: everything Max does, plus the ability to ingest images and video as first-class inputs and act on what it sees.
The word "plus" undersells what was added. Qwen3.7-Plus brings five agentic capabilities on top of visual understanding: deep reasoning, self-programming (the model writes and revises its own code), tool invocation (calling external APIs and functions), verification and testing (running outputs and checking results), and autonomous iteration (looping until the task is done). These aren't features listed on a spec sheet. They're the components of an agent that can take a task from screenshot to shipped result with no human in the loop.
Alibaba's positioning for this is "multimodal interactive hybrid agent" - a model that moves fluidly between visual perception and command-line execution, between reading a UI and writing the code to replicate it, between understanding a design reference and generating the corresponding frontend. The 1M-token context window, carried over from the rest of the Qwen3.7 family, means these multi-step workflows don't collapse under the weight of their own context. Long traces from 1,000+ tool calls stay coherent. Prior code and intermediate outputs remain accessible.
The Benchmark Case for Qwen3.7-Plus
Benchmark tables are only useful if you know which numbers to read first. For Qwen3.7-Plus, the most informative numbers are the ones that measure what the model does with visual input - not just whether it can describe an image, but whether it can use one.
On ScreenSpot Pro, which measures the ability to identify and click specific UI elements on real application screens, Qwen3.7-Plus scores 79.0% - above GPT-5.4 (67.4%), Gemini-3.1 Pro (68.1%), and Qwen3.6-Plus (68.2%). This is not a trivial capability. Locating the right button in a dense, real-world interface under instruction requires understanding layout, intent, and spatial relationships simultaneously.
On AndroidWorld, which evaluates end-to-end task completion in real Android app environments, Qwen3.7-Plus scores 81.0% - above Gemini-3.1 Pro (70.7%) and Qwen3.6-Plus (67.2%). On OSWorld-Verified, desktop computer use, the score is 73.3% - competitive with Claude Opus-4.6 Max (72.7%) and GPT-5.4 (75.0%).
These three benchmarks together describe a model that can navigate real software on real devices. Not simulate it. Not describe what it would do. Actually do it.
The multimodal reasoning profile is equally strong. On BabyVision - a benchmark measuring spatial reasoning and early visual cognition tasks - Qwen3.7-Plus scores 70.4%, a substantial jump over Qwen3.6-Plus (37.4%) and above Gemini-3.1 Pro (55.9%). On CharXiv(RQ), scientific chart reasoning, Qwen3.7-Plus scores 85.9%, above GPT-5.4 (84.5%). On HiPhO, physical commonsense reasoning over visual scenes, it scores 84.1%, above GPT-5.4 (65.0%) and near Gemini-3.1 Pro (85.4%). On MathVision, visual mathematical reasoning, Qwen3.7-Plus scores 90.3%, second only to GPT-5.4 (91.0%).
On document understanding, OmniDocBench 1.5 gives Qwen3.7-Plus 91.4% - the highest of all evaluated models, above Qwen3.6-Plus (91.2%), Gemini-3.1 Pro (90.0%), and Claude Opus-4.6 Max (86.6%). For teams processing mixed-format enterprise documents, this benchmark directly translates to production accuracy on PDFs with embedded tables, charts, and formulas.
For multimodal knowledge retrieval - vision combined with live search - SimpleVQA gives Qwen3.7-Plus 81.7%, above GPT-5.4 (69.4%) and Gemini-3.1 Pro (76.9%). WorldVQA gives it 61.1%, near Claude Opus-4.6 Max (65.4%) and well above Gemini-3.1 Pro (56.1%). On MMSearchPlus, which requires combining visual evidence with real-time web retrieval, Qwen3.7-Plus scores 41.4%, on par with Gemini-3.1 Pro (42.0%) and above Claude Opus-4.6 Max (38.9%).
Opus-4.6 Max | K2.6 Thinking | GLM-5.1 Thinking | DeepSeek-V4-Pro Max | Qwen3.6-Plus | Qwen3.7-Plus | |
|---|---|---|---|---|---|---|
Coding Agent | ||||||
Terminal Bench 2.0-Terminus | 65.4 | 66.7 | 63.5 | 67.9 | 61.6 | 70.3 |
SWE-Verified | 80.8 | 80.2 | -- | 80.6 | 78.8 | 77.7 |
SWE-Pro | 57.3 | 59.5 | 58.8 | 59.0 | 56.6 | 57.6 |
SWE-Multilingual | 77.5 | 76.7 | -- | 76.2 | 73.8 | 75.8 |
NL2repo | 47.6 | 42.8 | 41.0 | 35.5 | 34.4 | 41.1 |
SciCode | 51.9 | 52.2 | 45.1 | -- | 41.4 | 51.3 |
QwenWebDev | 1617 | -- | 1564 | 1570 | 1500 | 1536 |
QwenSVG | 1541 | 1325 | 1605 | 1506 | 1432 | 1588 |
General Agent | ||||||
Qwenclaw | 65.5 | 54.7 | 58.7 | 59.2 | 57.2 | 61.8 |
CoWorkBench | 68.2 | 58.2 | 66.0 | 66.3 | 64.5 | 65.1 |
ClawEval | 70.4 | 61.5 | 62.7 | 58.4 | 57.1 | 62.7 |
Skillsbench | -- | 56.2 | 53.1 | 52.3 | 45.7 | 54.9 |
BFCL-V4 | 76.7 | 71.3 | 70.9 | 70.6 | 68.9 | 72.9 |
MCP-Mark | 56.7 | 55.9 | 57.5 | 57.1 | 48.2 | 58.7 |
MCP-Atlas | 75.8 | 66.6 | 71.8 | 73.6 | 74.1 | 73.2 |
Vitabench | -- | 39.1 | 45.1 | 51.9 | 42.8 | 45.6 |
Deep-Planning | 58.9 | 42.3 | 34.1 | 44.6 | 40.9 | 62.3 |
SpreadSheetBench-v1 | 89.3 | 84.5 | 85.2 | 84.9 | 80.2 | 86.3 |
Kernel Bench L3 | 2.63/98% | 1.41/80% | 2.00/78% | 1.07/54% | 1.03/48% | 2.06/98% |
QwenWorldBench | 56.1 | 50.9 | 50.2 | 52.3 | 47.6 | 62.1 |
STEM & Reasoning | ||||||
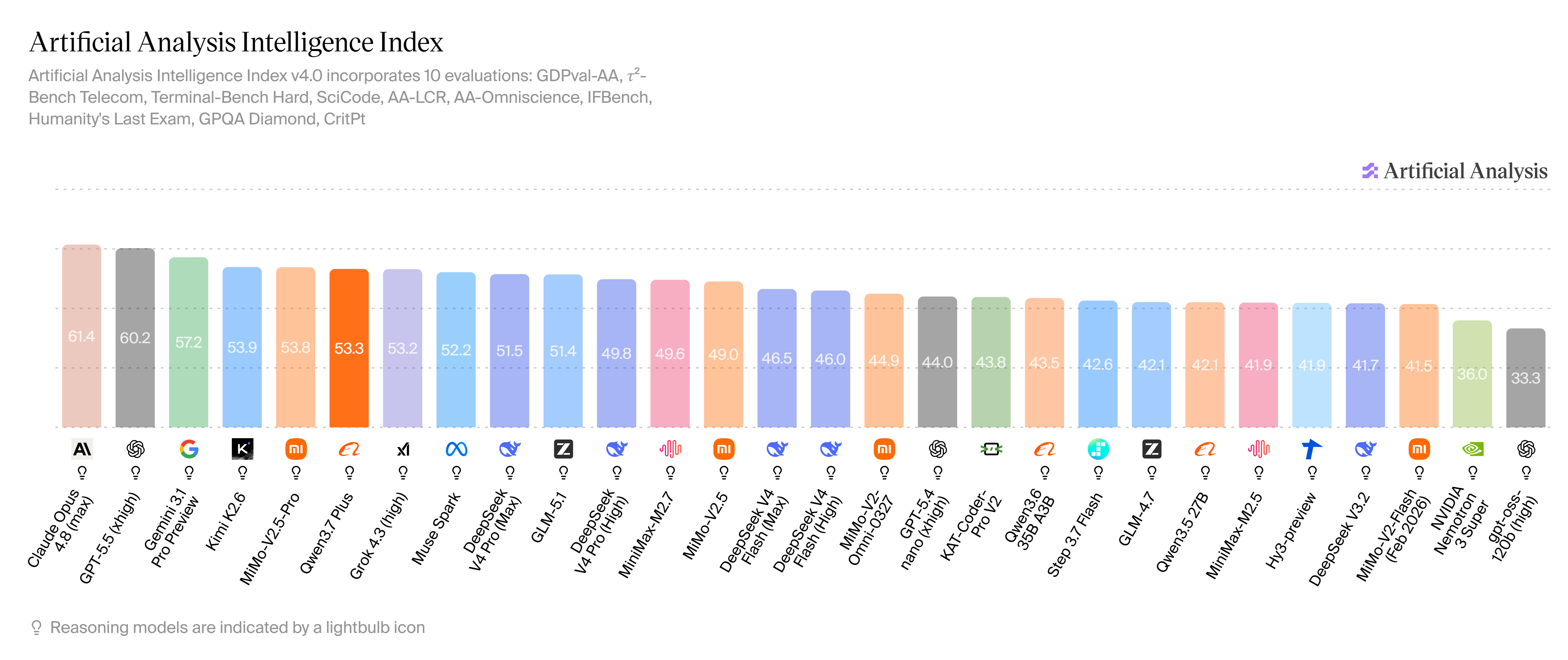
GPQA Diamond | 91.3 | 90.5 | 86.2 | 90.1 | 90.4 | 90.3 |
HLE | 40.0 | 36.4 | 34.7 | 37.7 | 28.8 | 34.7 |
LiveCodeBench | 88.8 | 89.6 | -- | 93.5 | 87.1 | 89.6 |
HMMT 2026 Feb | 96.2 | 92.7 | 89.4 | 95.2 | 87.8 | 92.9 |
IMOAnswerBench | 75.3 | 86.0 | 83.8 | 89.8 | 83.8 | 86.0 |
CritPT | 12.6 | 8.0 | 4.6 | 12.9 | 2.9 | 6.0 |
Apex | 34.5 | 24.0 | 11.5 | 38.3 | 8.8 | 22.7 |
General Capability | ||||||
MMLU-Pro | 89.7 | 87.1 | 86.3 | 87.5 | 88.5 | 88.5 |
MMLU-Redux | 95.2 | 95.3 | 94.3 | 94.8 | 94.5 | 94.5 |
SuperGPQA | 72.5 | 71.3 | 68.0 | 69.9 | 71.6 | 71.4 |
IFEval | 91.9 | 94.5 | 94.5 | 91.9 | 94.3 | 94.6 |
IFBench | 62.5 | 76.0 | 76.0 | 77.0 | 74.2 | 79.1 |
MRCR-v2 128k | 84.0 | 63.1 | 62.0 | 74.4 | 85.9 | 91.7 |
Multilingualism | ||||||
WMT24++ | 82.7 | 81.6 | 81.8 | 82.2 | 84.3 | 84.6 |
MAXIFE | 81.3 | 87.7 | 87.7 | 88.9 | 88.2 | 88.8 |
MMMLU | 90.6 | 87.5 | 87.2 | 87.9 | 89.5 | 89.0 |
MMLU-ProX | 86.1 | 83.7 | 83.9 | 83.9 | 84.7 | 85.4 |
NOVA-63 | 59.1 | 56.7 | 54.6 | 52.8 | 57.9 | 58.8 |
INCLUDE | 87.4 | 84.2 | 84.3 | 86.1 | 85.1 | 83.0 |
Global PIQA | 91.2 | 89.2 | 89.5 | 90.5 | 89.8 | 90.3 |
PolyMATH | 80.2 | 82.7 | 67.6 | 72.0 | 77.4 | 84.0 |
The text-side benchmarks are similarly competitive. On Terminal-Bench 2.0, the agentic terminal execution benchmark, Qwen3.7-Plus scores 70.3% - the highest of all evaluated models including Claude Opus-4.6 Max (65.4%), DeepSeek-V4-Pro Max (67.9%), and Kimi K2.6 Thinking (66.7%). On Deep-Planning, which measures multi-step planning under uncertainty, Qwen3.7-Plus scores 62.3% - again the highest, above Claude Opus-4.6 Max (58.9%) and well above DeepSeek-V4-Pro Max (44.6%). On GPQA Diamond, frontier science reasoning, it scores 90.3%, competitive across the board.
What 11 Hours of Autonomous Development Actually Looks Like
Benchmark numbers describe capability. A real-world demo describes how that capability behaves under extended autonomous execution.
Alibaba's internal demonstration of Qwen3.7-Plus's Hybrid-Agent system is worth describing precisely, because it maps directly to the benchmark scores rather than being separate from them.
The task: build a complete English vocabulary learning app, from scratch, end to end. The agent operated continuously for over 11 hours without human intervention. It generated more than 10,000 lines of code, triggered over 1,000 agent calls, and completed every stage of a real software development lifecycle: requirement document generation, automated coding, installation and deployment, test case creation, GUI-based automated testing, multi-scenario parallelized testing, automatic product documentation updates, and autonomous version iteration.
That is not a demo designed to hit a benchmark. It is the Terminal-Bench and Deep-Planning numbers made visible. An agent that scores 70.3% on Terminal-Bench is an agent that can sustain coherent, productive execution across a multi-hour task without losing the thread. A model that scores 62.3% on Deep-Planning is one that can decompose "build a vocabulary app" into a correct, ordered dependency graph and execute it stage by stage.
The second demo is arguably more precise as a technical proof point. The task was to reproduce the native macOS Stocks application - a professional, data-connected desktop application - using only autonomous interaction with the original app as input. The agent studied the native app's UI layout and feature details through interaction, wrote SwiftUI source code from those interaction records, integrated a live market data API, compiled and launched the reproduced app, and then ran 10 functional verification tests autonomously - checking real-time quote loading, stock switching, multi-period view toggling, search filtering, and the detailed stats panel. All 10 tests passed. Dark theme, split-view layout, real-time data, full interactivity: faithfully reproduced.
This is what ScreenSpot Pro 79.0% and AndroidWorld 81.0% mean in practice.
Vision-to-Code: The Capability That Eliminates an Entire Pipeline Stage
The capability that most directly affects production workflows for AI builders and engineering teams is Qwen3.7-Plus's vision-to-code generation. Not because it is the most impressive benchmark number, but because it replaces a pipeline stage that currently requires multiple models, multiple prompts, and usually a human reviewer.
On QwenVision2Code, which evaluates the ability to turn visual inputs into executable code, Qwen3.7-Plus scores 1,772 - well above Qwen3.6-Plus (1,522) and Gemini-3.1 Pro (1,632), and below GPT-5.4 (1,884). In practice, this capability spans: SVG generation from images and video, full webpage generation from design references or video materials, frontend code from UI screenshots, and component generation from design files. The model does not describe the visual structure and ask you to write the code. It writes the code.
The pattern that makes this compound in value is what Qwen3.7-Plus does after it generates the code: it runs it, checks the output against the visual reference, identifies discrepancies, and revises. The generate-run-check loop is what separates a vision-to-code model from a useful vision-to-code agent. On benchmarks like OSWorld-Verified and AndroidWorld, this loop is precisely what is being evaluated - not just "did it write code that looks right" but "did it produce something that works."
For enterprise document workflows, the same compound applies. Qwen3.7-Plus scoring 91.4% on OmniDocBench means it can extract structured data from a complex mixed-format document. Its multimodal search integration means it can supplement that extraction with live web knowledge. Its code generation means it can turn that extracted data into a structured output, a populated template, or a triggered API call - without a human transcription step in between.
The Agentic Architecture: Why 1M Context and Tool Chaining Together Matter
Most agent frameworks fail around the 100-tool-call mark. The model loses context coherence - earlier tool outputs become inaccessible, plans drift from their original structure, and subsequent actions start hallucinating prior state. This is not a prompting problem. It is a context management problem.
Qwen3.7-Plus is built for the long trace. The 1M-token context window, shared with Qwen3.7-Max, means that 1,000+ sequential tool calls - demonstrated both in the vocabulary app run and in the macOS Stocks reproduction - do not cause the model to lose its place. Code written at step 200 is still correctly referenced at step 800. A test that failed at step 350 is still in context when the model revises its approach at step 600.
On MCP-Mark, which evaluates model capability within Model Context Protocol tool-use environments, Qwen3.7-Plus scores 58.7% - the highest of all evaluated models including Claude Opus-4.6 Max (56.7%) and DeepSeek-V4-Pro Max (57.1%). On BFCL-V4, function-calling reliability, it scores 72.9%, above Kimi K2.6 Thinking (71.3%) and DeepSeek-V4-Pro Max (70.6%). On KernelBench L3, low-level GPU kernel optimization, Qwen3.7-Plus achieves a median speedup of 2.06x over PyTorch eager reference with 98% of problems beating torch.compile - matching Claude Opus-4.6 Max's 2.63x/98% profile and well above all other evaluated models.
The cross-harness generalization is also worth noting for teams that have already committed to a specific agent framework. Qwen3.7-Plus integrates natively with Claude Code (via Anthropic API protocol compatibility), OpenClaw, and Qwen Code. You can point your existing scaffold at Qwen3.7-Plus by changing the model string and the base URL. The model generalizes across frameworks - it doesn't require a proprietary harness to perform.
For teams using Open Source Models specifically, the integration is direct:
MODEL NAME = "Qwen/Qwen3.7-Plus"
QUBRID_BASE_URL = https://platform.qubrid.com/v1Same tooling, different model, immediate access to multimodal capabilities your existing text-only setup doesn't have.
What Qwen3.7-Plus Means for Different Builder Profiles
For frontend engineers and design-to-code teams: Vision-to-code at QwenVision2Code 1,772 means Qwen3.7-Plus can accept a Figma export, a reference screenshot, or a video walkthrough and produce functional frontend code - HTML, CSS, React, SwiftUI - without a manual transcription step. It closes the loop between design and deployment in a way that text-only models never could, because text-only models require someone to translate the visual specification into words first.
For agent builders: Terminal-Bench 70.3% and Deep-Planning 62.3% - both best-in-class across evaluated frontier models - mean Qwen3.7-Plus is the strongest foundation available today for building agents that need to sustain long-horizon, multi-step execution across real environments. The 11-hour, 1,000+ tool-call vocabulary app demo is the proof-of-concept. The benchmarks are the guarantee that it generalizes.
For enterprise document and data teams: OmniDocBench 91.4% and OCR-Bench-V2 English 70.7% (above GPT-5.4 at 59.1% and Gemini-3.1 Pro at 64.6%) mean Qwen3.7-Plus processes real-world business documents - invoices, contracts, research papers, financial reports - with best-in-class accuracy. Combined with multimodal search integration (SimpleVQA 81.7%, MMSearchPlus 41.4%), the model can supplement document extraction with live external knowledge, eliminating the gap between "what's in the document" and "what the document means given current context."
For computer use and GUI automation teams: AndroidWorld 81.0% and ScreenSpot Pro 79.0% are the numbers that matter. They translate directly to: your agent can navigate a real mobile app, click the right elements, respond to dynamic content, and complete multi-step tasks - across both Android and desktop environments - at a reliability level that makes production deployment realistic rather than aspirational.
For multilingual product teams: On PolyMATH, Qwen3.7-Plus scores 84.0% - the highest of all evaluated models including Kimi K2.6 Thinking (82.7%) and Claude Opus-4.6 Max (80.2%). WMT24++ translation gives it 84.6% and IFBench instruction following gives it 79.1%, also top-tier. For teams building AI products that need to perform consistently across languages, this matters beyond the headline accuracy numbers - it means the model's reasoning and agent capabilities are not degraded in non-English contexts
Why Access Qwen3.7-Plus Through Qubrid AI
Qubrid AI gives you access to Qwen3.7-Plus from day one, through the same unified API you use for every other model on the platform. No new account, no separate provisioning, no managing multiple credential sets across model providers simultaneously.
The practical value of this for teams evaluating Qwen3.7-Plus is the ability to run side-by-side comparisons on your own workloads - your documents, your UI screenshots, your agent tasks - against other models you are already using, using infrastructure you already have. Qwen3.7-Plus's vision-to-code capability is genuinely strong on benchmarks. But the benchmark that matters for your product is the one you run on your own data. Qubrid makes that experiment fast.
For teams that want to route by modality - text-only traffic to a text-optimized model, image or video inputs to Qwen3.7-Plus - Qubrid's platform supports that routing without forcing you to maintain separate API integrations per model. You change the model string, not the infrastructure.
20% Off for Early Adopters
Qubrid AI is offering 20% off Qwen3.7-Plus access for a limited time to mark the launch.
If you are building agentic systems, multimodal document pipelines, GUI automation workflows, or frontend generation tools - this is the experiment to run. The model is ready, the API is live, and the discount window is limited.
Access Qwen3.7-Plus on Qubrid AI: https://platform.qubrid.com/model/qwen3.7-plus
What Qwen3.7-Plus Signals About Where Multimodal AI Is Going
The standard narrative about multimodal models has been that vision is an add-on - useful for specific tasks, but not architecturally central to what a model is. Qwen3.7-Plus challenges that narrative directly.
The reason the vocabulary app demo runs for 11 hours without human intervention is not because the model was given an unusually simple task. It is because the model can close loops that previously required human judgment: seeing that a UI element looks wrong, deciding how to fix it, writing the fix, running the test, and confirming the result, all within the same agent context. Each of those steps, done by a human, represents a context switch and a delay. A model that can close the loop makes the whole cycle faster.
The reason ScreenSpot Pro 79.0% and AndroidWorld 81.0% are the right benchmarks to watch is not that they are the highest absolute numbers in the table. It is that they measure something qualitatively different from text generation: reliable action in the world. A model that can identify the right button to click and click it, across real applications, at 79-81% reliability, is a model that can be deployed into workflows that previously required a human operator.
The broader trajectory here is not that vision became another benchmark category. It is that vision, combined with tool use and long-context coherence, changes what an agent can be assigned to do. Qwen3.7-Plus is among the first models that makes this concrete rather than theoretical.
Try Qwen3.7-Plus on Qubrid AI - 20% off early adopter access: https://platform.qubrid.com/model/qwen3.7-plus