MiniMax M3 Is Now Available on Qubrid AI
There's a version of AI progress that moves in headlines: a new model drops, benchmarks circulate on X, and by the time most developers actually integrate the thing, the discourse has already moved on to the next release. MiniMax M3 deserves a slower read than that.
Released today, MiniMax M3 is a technically significant model for reasons that go beyond any benchmark table - though the benchmarks are genuinely impressive. What makes M3 matter is the convergence of three capabilities that, until now, frontier models have only achieved in isolation: coding performance that rivals the best closed-source models, a one-million-token context window built on a novel sparse attention architecture, and native multimodality trained from the ground up rather than bolted on after the fact. M3 is the first open-weight model to bring all three together in a single unified system.
We're proud to announce that MiniMax M3 is available on Qubrid AI starting today, from Day 0 of launch. Developers, AI teams, and builders can access M3 immediately through the Qubrid AI platform, with no waitlists, no preview queues, and no friction. For a limited time, early adopters receive 50% off - more on that below.
Why the Architecture Matters Before the Benchmarks
Most launch announcements start with numbers. This one starts with attention mechanisms, because the architectural story here actually explains why the numbers are what they are.
The central innovation in MiniMax M3 is MSA - MiniMax Sparse Attention - a new attention architecture developed entirely by the MiniMax team. If you've worked with long-context models before, you know the core tension: full attention produces high-quality outputs but scales quadratically with context length, which makes million-token windows computationally impractical at inference time. Sparse attention has been the theoretical answer to this for years, but existing implementations (DSA, MoBA, and others) tend to accumulate approximation errors that degrade performance in practice.
MSA takes a different approach. Rather than approximating attention from a query-centric view, it partitions the KV cache into blocks and uses a "KV outer gather Q" method - treating KV blocks as the outer loop and aggregating only the queries that fall within each block's relevance window. The result: each block is read exactly once, memory access is contiguous, and arithmetic intensity is dramatically improved. Compared with common sparse methods, MSA is more than 4x faster than open-source Flash-Sparse-Attention and flash-moba.
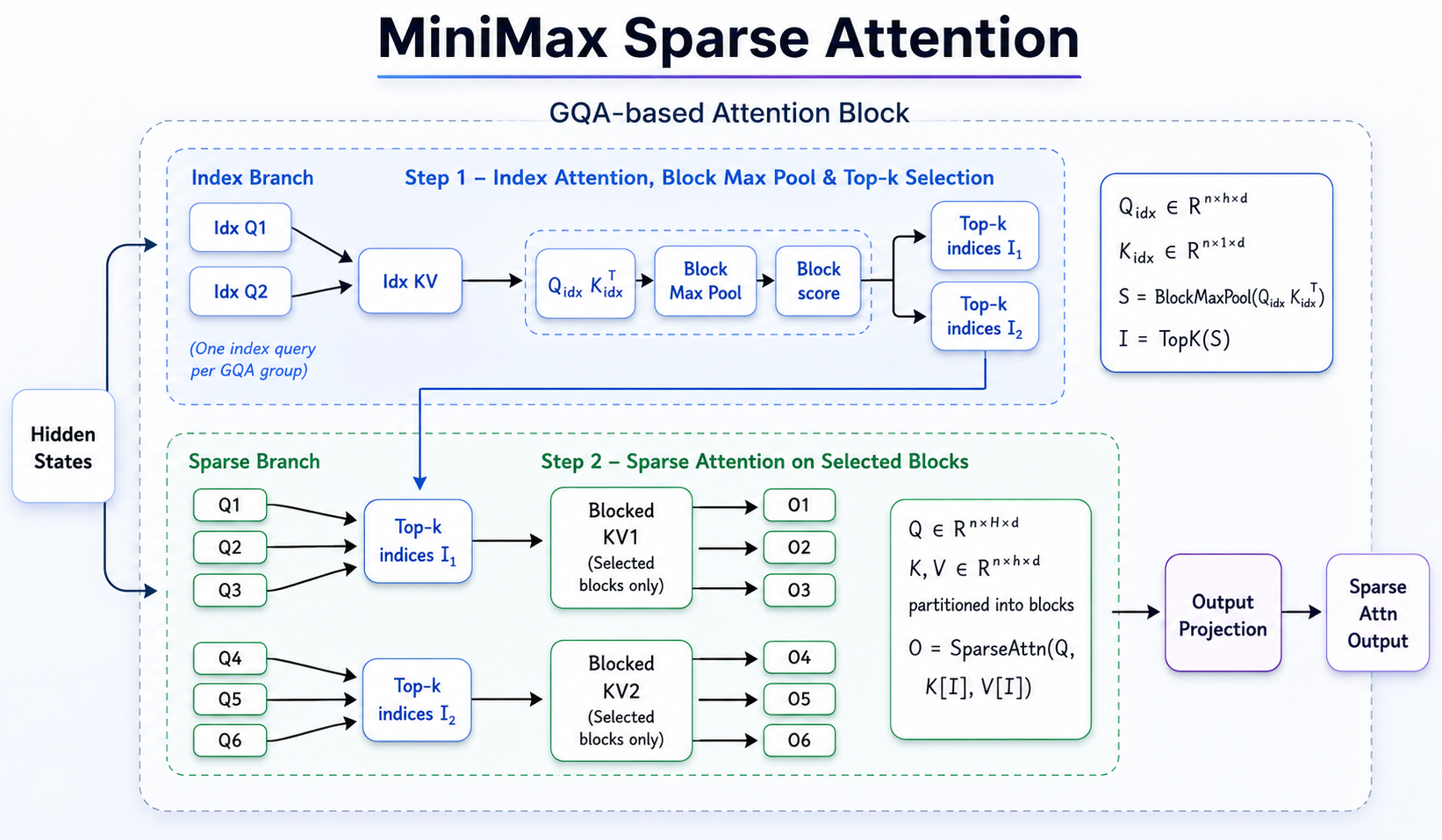
The engineering result: at a context length of 1 million tokens, M3's per-token compute is 1/20th that of the previous-generation model. Prefilling is more than 9x faster. Decoding is more than 15x faster. Across multiple ablations, MSA matched full attention on the vast majority of capabilities.
The punchline is that these gains are realized in production, not just in theory. A 1M-context window is not a marketing ceiling you'll never actually hit - it's an operational parameter you can deploy against today. For anyone building RAG pipelines over large codebases, document-heavy enterprise workflows, or multi-session agent loops, this changes what's actually feasible at a reasonable cost.
Frontier Coding and Agentic Capabilities: What the Numbers Actually Mean
The phrase "frontier coding" gets used loosely in AI announcements, so it's worth being specific about what MiniMax's claim means and what evidence supports it.
Here is the full benchmark picture from the official release, compared across MiniMax M3, MiniMax M2.7, Claude Opus 4.7, GPT 5.5, Gemini 3.1 Pro, Claude Sonnet 4.6, DeepSeek V4 Pro, GLM 5.1 Thinking, and Kimi K2.6 Thinking:
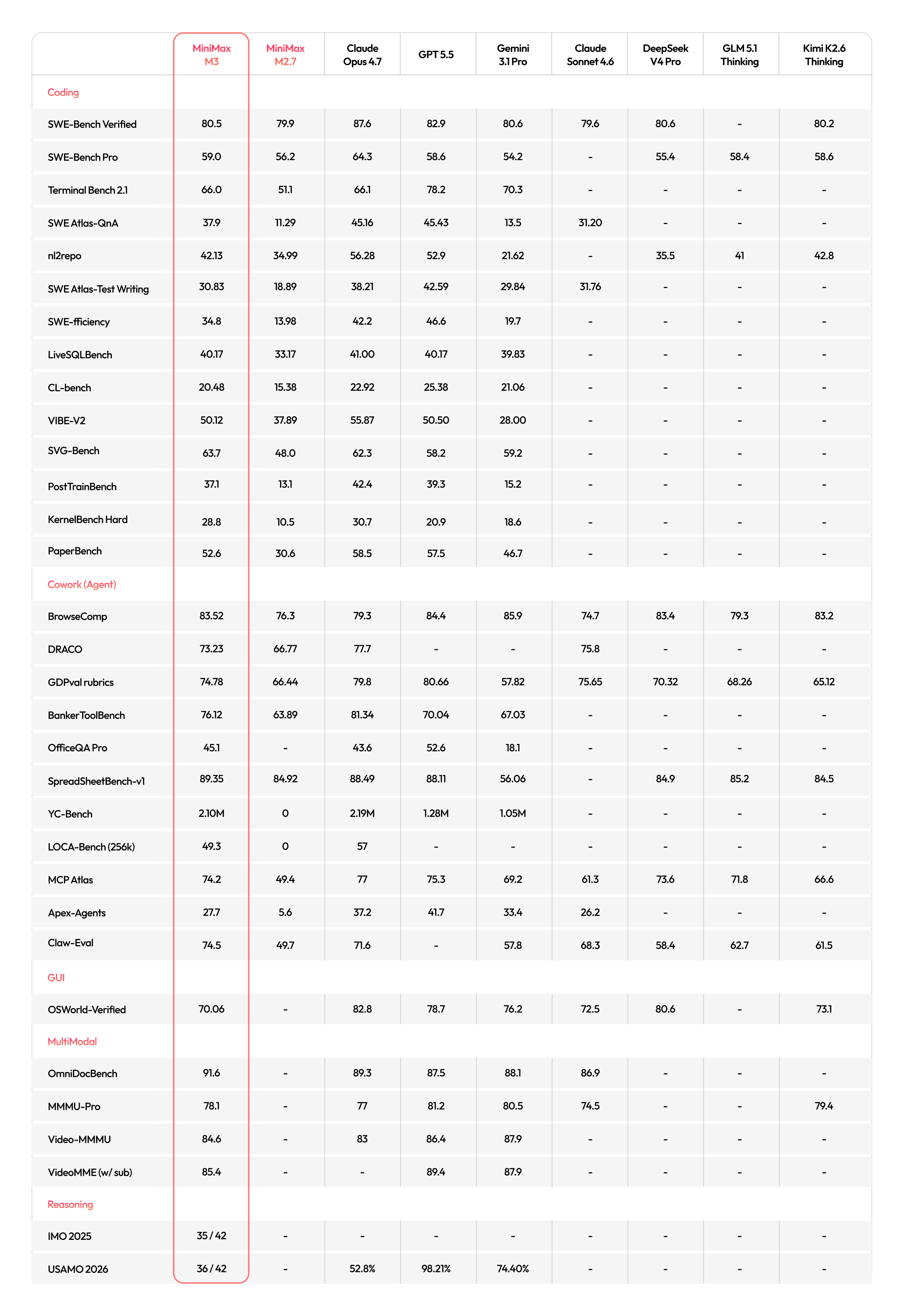
On SWE-Bench Pro - the most rigorous public evaluation for real-world software engineering - M3 scores 59.0%, surpassing both GPT-5.5 (58.6%) and Gemini 3.1 Pro (54.2%), and approaching Claude Opus 4.7 (64.3%). On Terminal-Bench 2.1, M3 scores 66.0%, matching Opus 4.7 (66.1%) and well ahead of Gemini 3.1 Pro (70.0% - notably, Gemini leads here; Terminal-Bench rewards a specific style of agentic terminal execution that Gemini appears well-tuned for). On SVG-Bench, M3 scores 63.7% - surpassing Opus 4.7 (62.3%), GPT-5.5 (58.2%), and Gemini 3.1 Pro (59.2%).
For agentic workloads specifically: MCP Atlas (model capability within tool-calling environments) gives M3 74.2%, while Opus 4.7 scores 77% and GPT-5.5 scores 75.3%. On Claw-Eval (end-to-end autonomous agent evaluation across 161 tasks), M3 reaches 74.5% - the highest score among all evaluated models. On SpreadSheetBench-v1, M3 leads with 89.35%. On BankerToolBench, M3 scores 76.12%, second only to Opus 4.7 (81.34%).
The multimodal story is compelling. On OmniDocBench, M3 scores 91.6% - the highest of any model in the comparison, above Opus 4.7 (89.3%), GPT-5.5 (87.5%), and Gemini 3.1 Pro (88.1%). On reasoning: IMO 2025 gives M3 35/42, and USAMO 2026 gives it 36/42 - the only model to report scores on these problems in this comparison.
These scores don't live in a vacuum. What makes M3's coding and agentic profile credible is how MiniMax validated it in practice.
The Real-World Tests That Justify the Benchmarks
Independent Paper Reproduction
MiniMax gave M3 an ICLR 2025 Outstanding Paper Award-winning paper, Learning Dynamics of LLM Finetuning, and asked it to reproduce the paper's core experiments autonomously. No hand-holding. No checkpoints. Just the paper and a working environment.
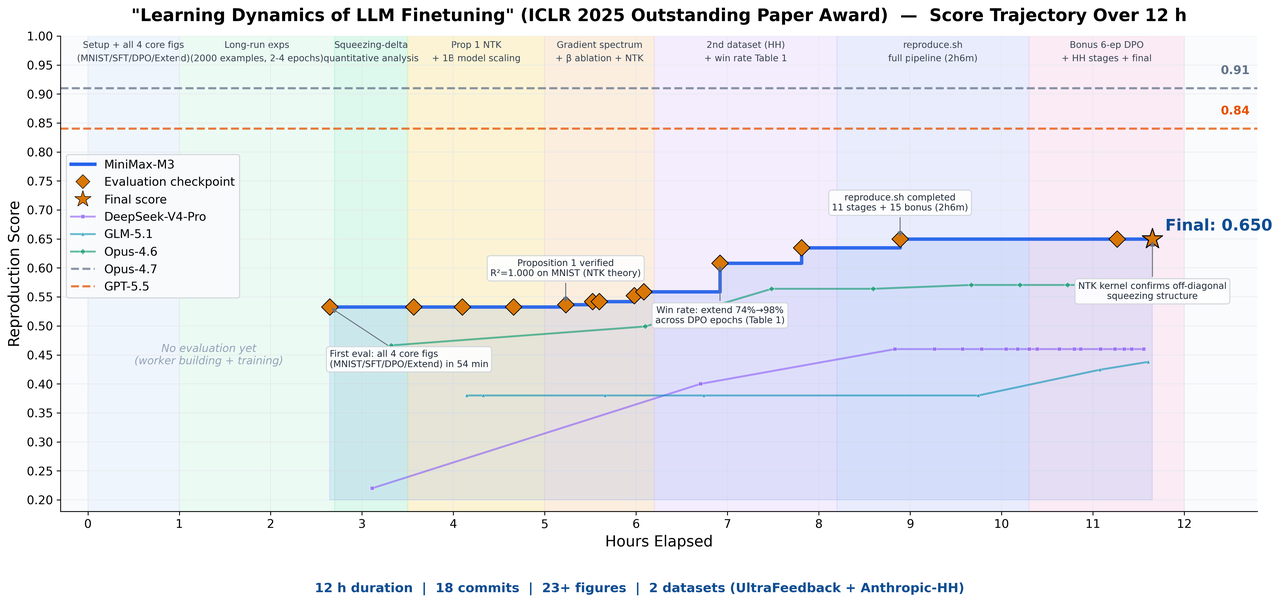
M3 ran for nearly 12 hours, produced 18 commits, and generated 23 experimental figures. It successfully matched the trend of prediction-probability changes during the SFT stage, observed the squeezing effect in the DPO experiments, and verified the Extend mitigation method described in the original paper. Multimodal capabilities were required to parse the curves, data, and formulas in the paper. Long context ensured the paper, code, and experiment logs could fit into the context window simultaneously. Strong coding and agent capabilities were required to sustain execution over the full thread. M3 handled all three.
CUDA Kernel Optimization
FP8 matrix multiplication (GEMM) is one of the most compute-intensive parts of large model inference, and among the most difficult to optimize by hand. On NVIDIA Hopper architecture GPUs, writing a production-grade FP8 GEMM kernel typically requires one to two weeks of focused effort from an experienced team.
MiniMax gave M3 a cold task: a description, a benchmark evaluation script, and a Triton skeleton that could not run directly. No reference implementation. The model had to start from first principles.
Over approximately 24 hours of continuous execution, M3 completed 147 benchmark submissions and 1,959 tool calls. It went through the full process: baseline implementation, autotune configuration generation, performance bottleneck diagnosis, CUDA Graph integration, persistent kernel rewriting, and host-side scheduling optimization - each step self-validated through benchmark feedback, with no human intervention.
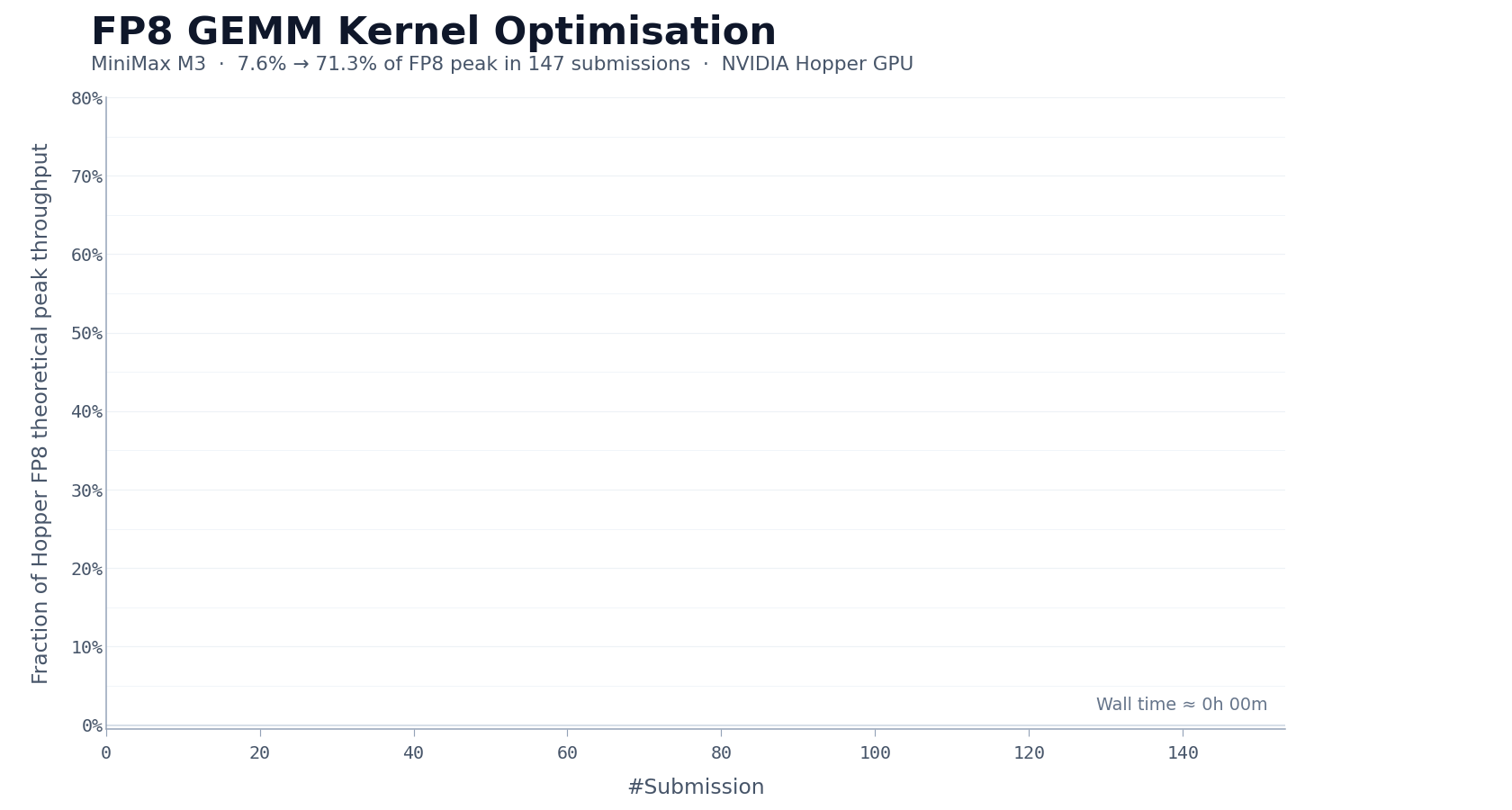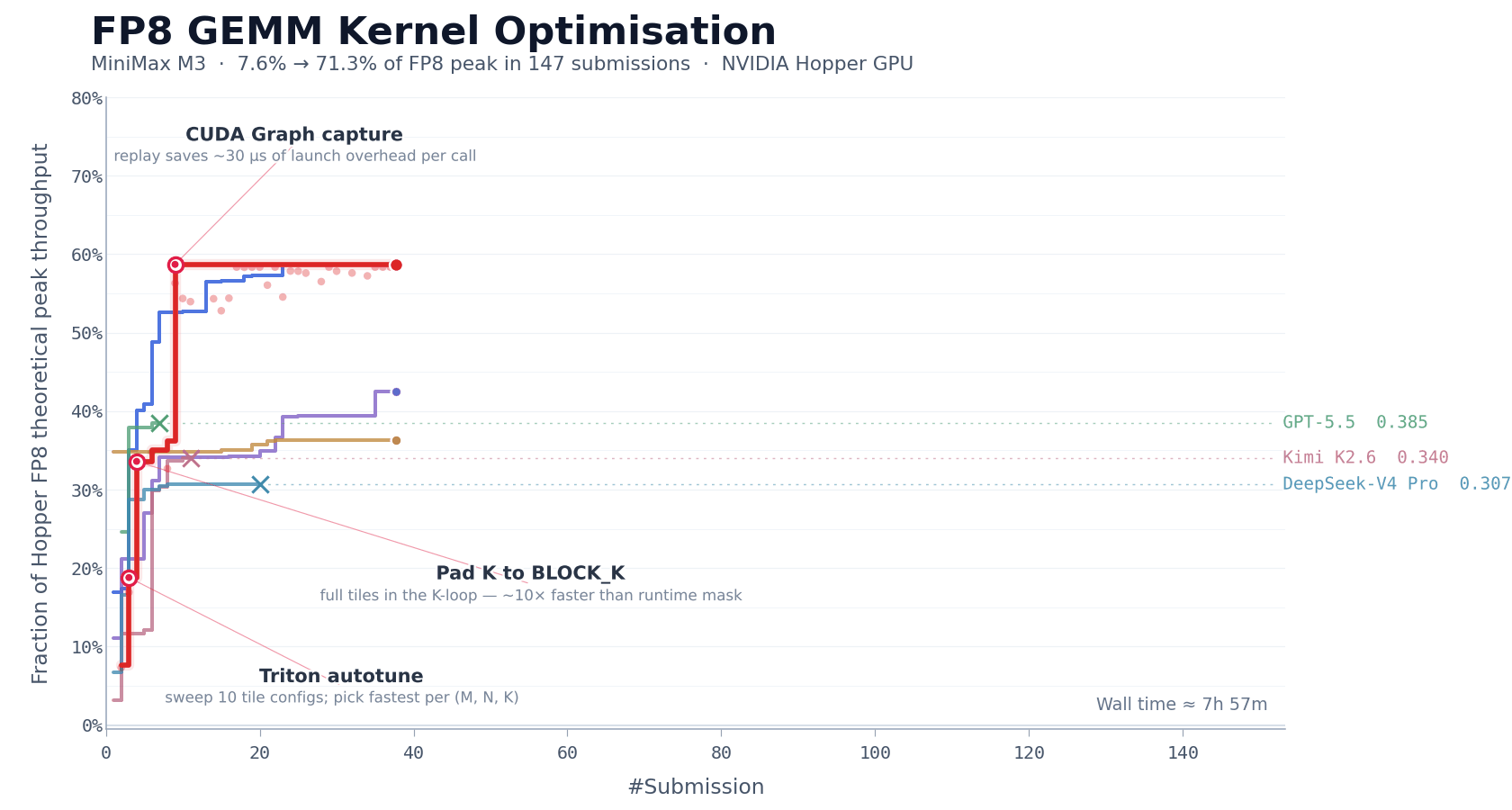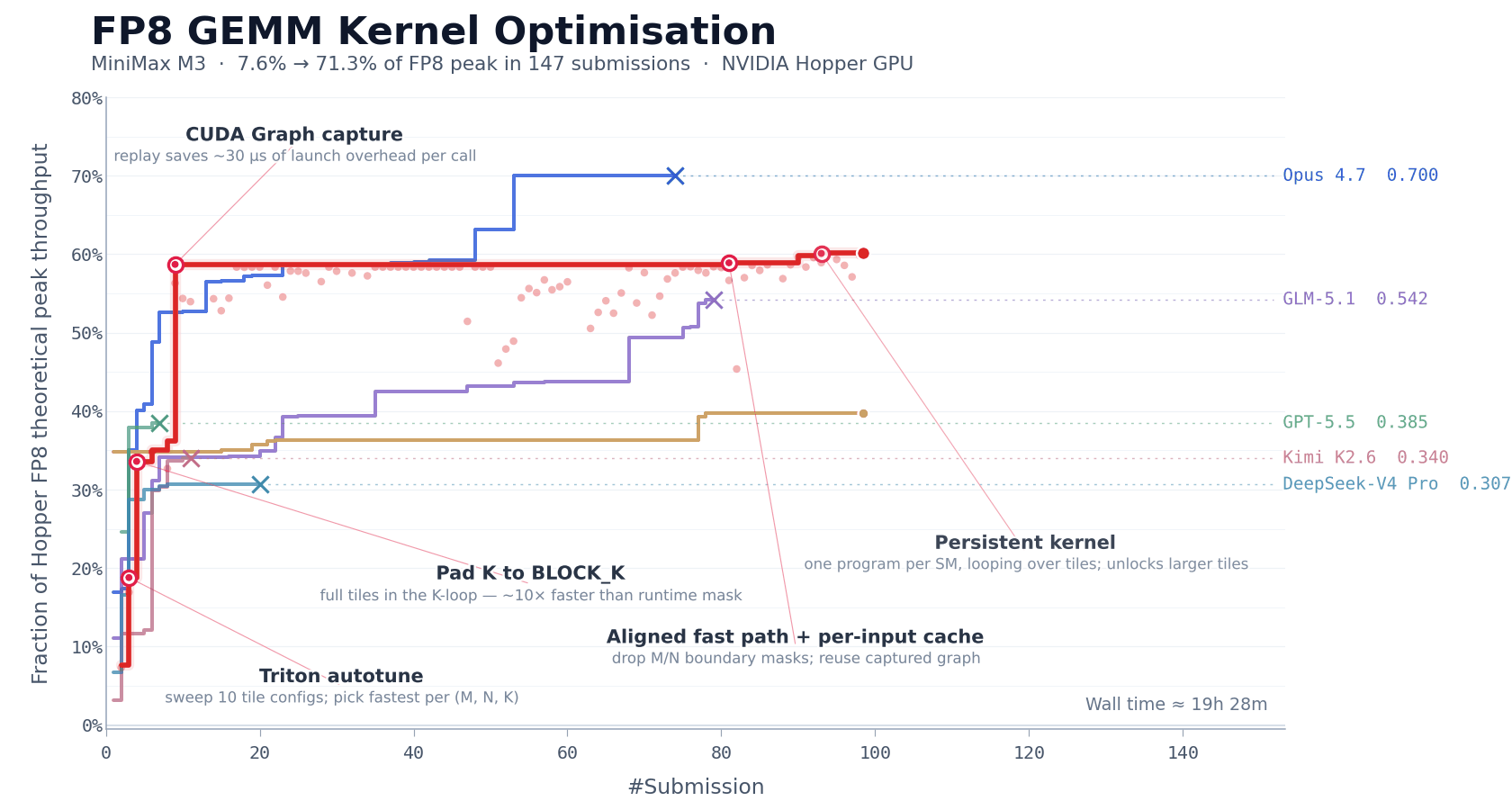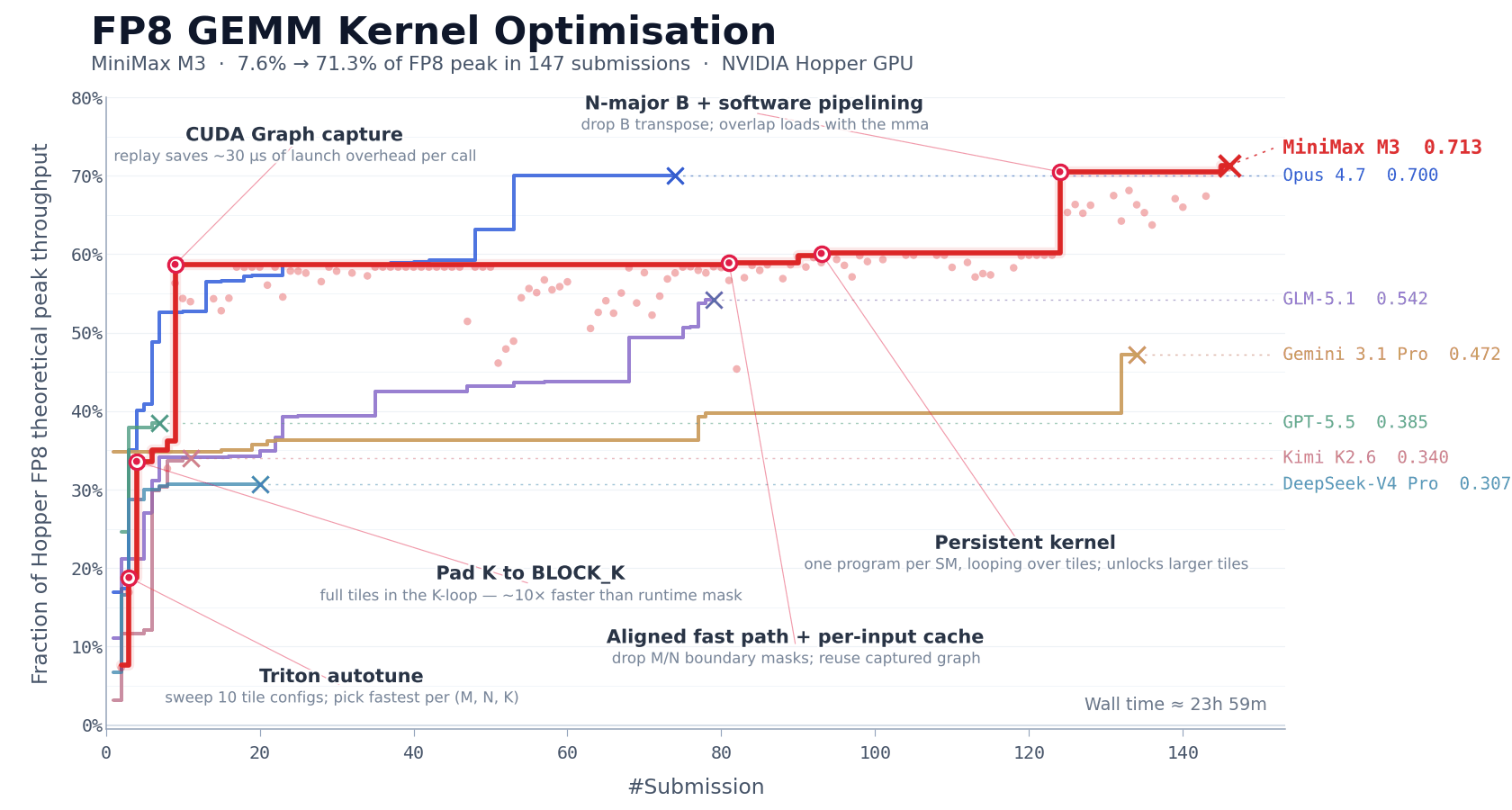
After six landmark rounds of optimization, M3 improved Hopper FP8 hardware peak utilization from 7.6% to 71.3% - a 9.4x speedup over the original version. Its best solution appeared on submission 145. Before that point, the model passed through multiple performance plateaus where progress stalled, yet it kept exploring. Most other models stopped making new progress within the first 30 submissions and exited. Only Opus 4.7 and M3 continued meaningfully past that point.
The capabilities required here go beyond code generation. The context produced by nearly 2,000 tool calls is highly structured and dense - this is precisely where MSA's long-context attention allocation mechanism played a critical role.
Letting M3 Train Models
PostTrainBench represents perhaps the most demanding autonomous AI task evaluated publicly: give M3 four base models that have completed pretraining but have no downstream capabilities, and have it run the full cycle of data synthesis, training, evaluation, and iteration autonomously within 12 hours. The goal: get those base models to acquire capabilities across mathematical reasoning (AIME2025), tool calling (BFCL), scientific reasoning (GPQA Main), arithmetic (GSM8K), and code generation (HumanEval).
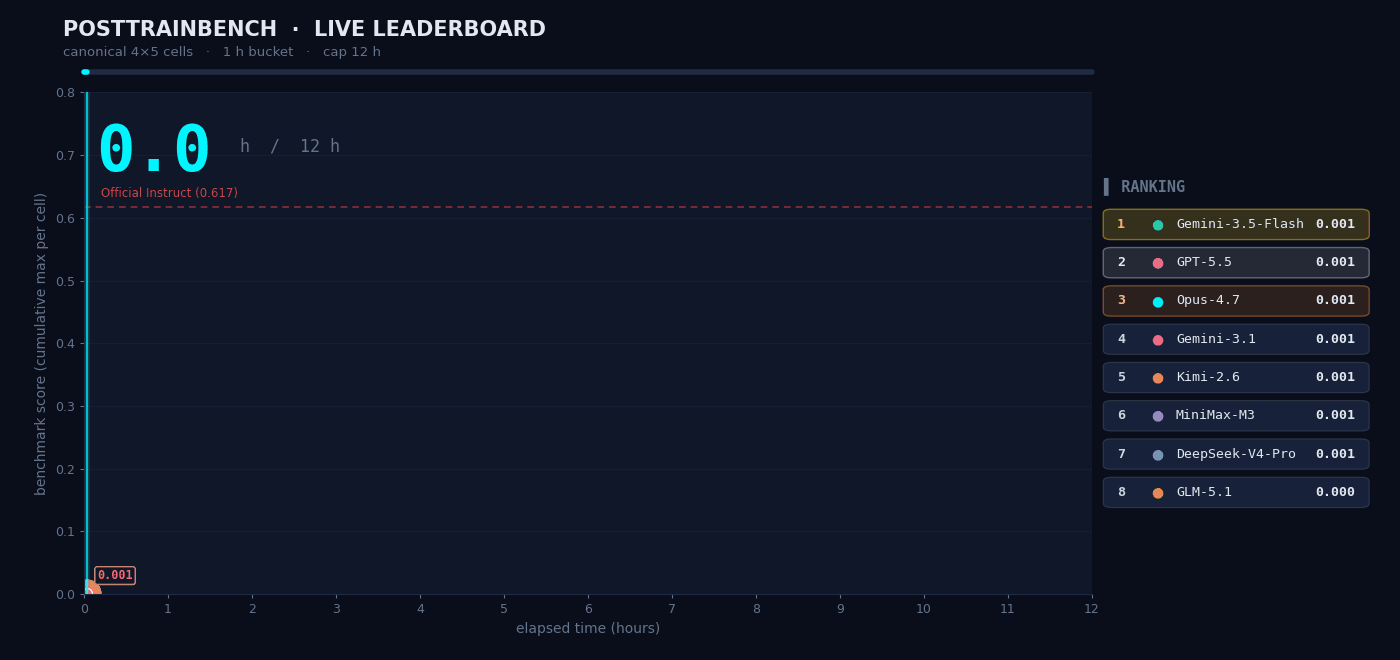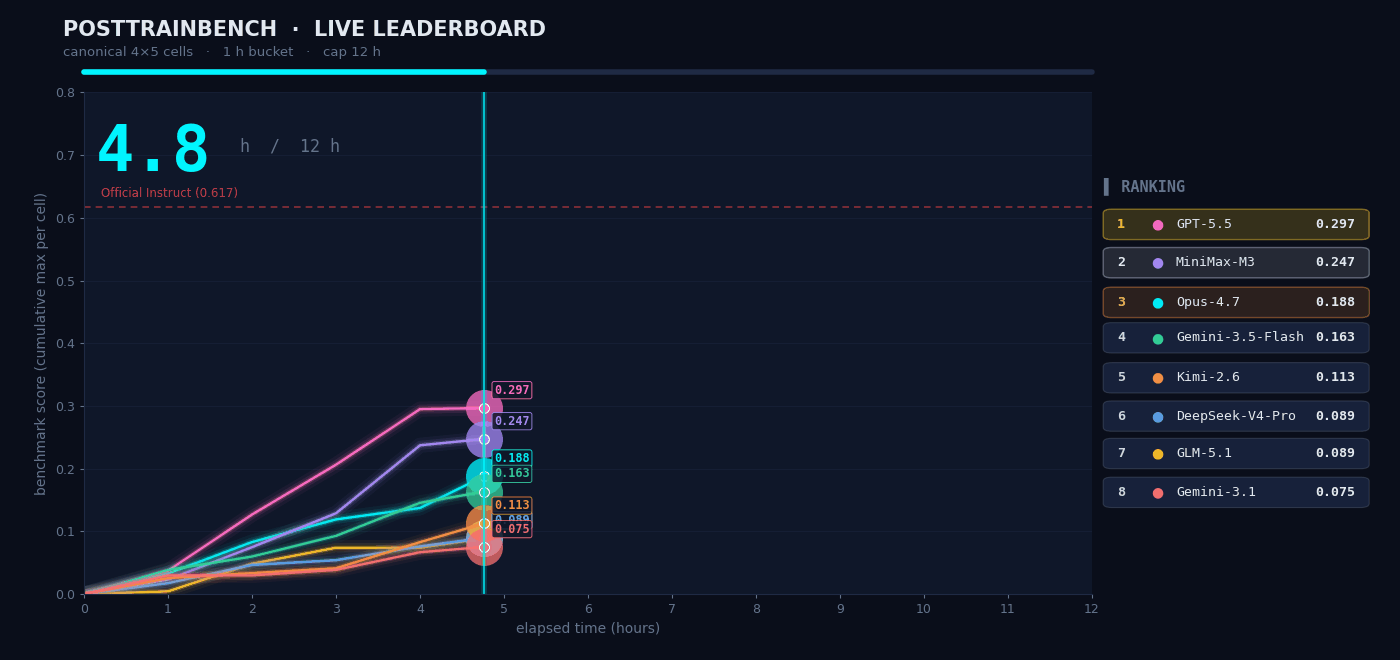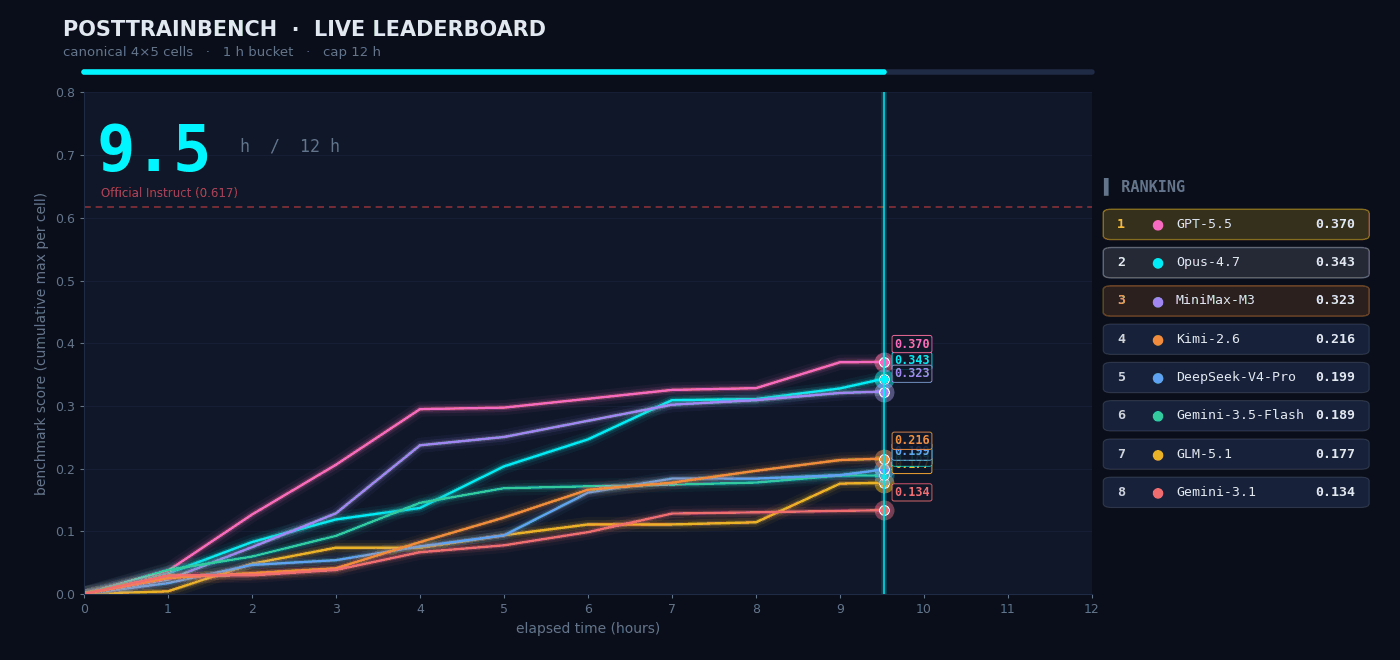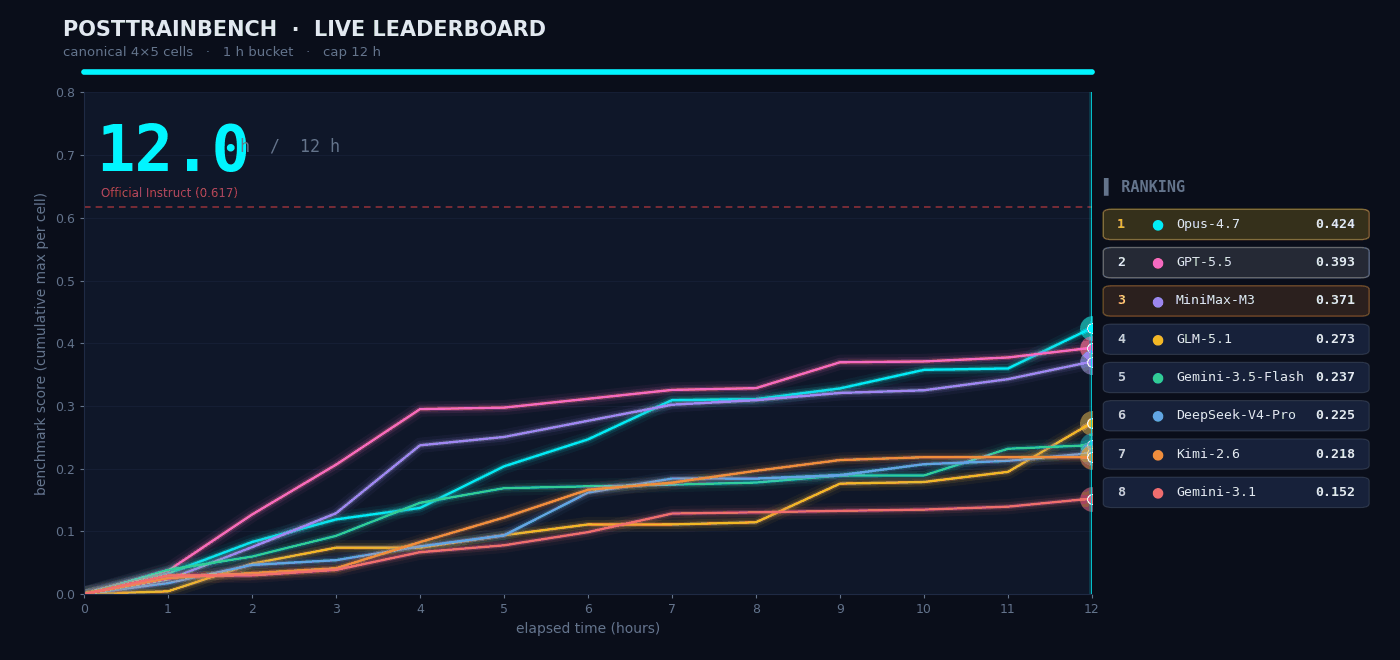
The entire "data synthesis to training to evaluation to iteration" loop ran without any human intervention. M3 scored 0.37 on PostTrainBench - slightly below Opus 4.7 (0.42) and GPT-5.5 (0.39), but clearly ahead of all other models including Gemini 3.1 Pro (0.15). In the full benchmark table above, M3 scores 37.1, above MiniMax M2.7 (13.1), GPT-5.5 (39.3), and Gemini 3.1 Pro (15.2).
Multimodality Built In, Not Bolted On
Most "multimodal" models today were text models first, with vision adapters added after the fact. The semantic spaces of different modalities in those architectures don't truly merge - they interact through a translation layer, which limits how naturally the model reasons across input types.
M3 was trained with interleaved multimodal data from Step 0. Text, images, and video are woven together in the training distribution rather than processed separately. MiniMax's research found that interleaved data is even more critical to multimodal performance improvement than previously assumed in the field - and they rebuilt the entire data pipeline around that finding, scaling training data to the order of 100 trillion tokens.
The practical results: on OmniDocBench (document understanding across charts, tables, formulas, and dense text layouts), M3 scores 91.6% - the best in class. On MMMU-Pro (expert-level multimodal academic reasoning), M3 scores 78.1%. On Video-MMMU, M3 scores 84.6%. On OSWorld-Verified (computer use, controlling desktop GUIs and navigating real applications), M3 achieves 70.06% - enabling use cases like reading a mobile screen and completing operations in a desktop ERP client without any human input.
Deep Technical Profile for Engineers
For teams evaluating M3 for production deployment, here are the specifics that matter:
Context and inference modes: M3 supports up to 1M-token context. API calls with 512K or fewer input tokens are billed at the standard rate, covering the vast majority of conversation and coding scenarios. Calls above 512K use a higher long-context rate, suited for full-repository understanding and ultra-long document parsing. Thinking can be toggled on or off at request time - thinking-enabled mode suits complex reasoning, agentic tasks, and long-horizon collaboration; thinking-disabled mode reduces latency for high-throughput scenarios like code completion or chat. Both modes share the same pricing.
Agentic reliability: 74.5% on Claw-Eval across 161 tasks, and 74.2% on MCP Atlas, make M3 the strongest available open-weight model for production agentic pipelines requiring reliable tool orchestration across long horizons.
Long-context retrieval: On LOCA-Bench at 256K context, M3 scores 49.3%, above MiniMax M2.7 (0). DRACO (deep research) gives M3 73.23%, second only to Opus 4.7 (77.7%). These translate directly to RAG architectures where the goal is precise synthesis over large corpora.
Open weights incoming: The full technical report and open-source model weights are scheduled for release within 10 days of today's launch. Engineering teams who want to fine-tune or self-host will have that option very shortly.
What the Benchmarks Mean for Your Specific Workload
Numbers need translation. Here is what M3's benchmark profile means for different categories of work:
AI coding assistants and IDE integrations: 59.0% on SWE-Bench Pro means M3 resolves a majority of realistic GitHub issues autonomously, including issues requiring multi-file changes, dependency management, and test writing. The interactive user simulator framework MiniMax built into M3's training - which models continuous multi-turn developer collaboration rather than single-shot task execution - means the model behaves more like an engineering collaborator than a code generator. 80.5% on SWE-Bench Verified further validates this.
Enterprise document intelligence: 91.6% on OmniDocBench means M3 can process mixed-format enterprise documents - PDFs with embedded tables, financial reports with charts, technical manuals with diagrams - with best-in-class fidelity. Combined with 1M-token context, this opens up workflows that weren't tractable before: feeding an entire document library into a single inference pass and getting synthesis rather than summaries.
Autonomous agents and tool-use pipelines: 74.5% on Claw-Eval and 74.2% on MCP Atlas make M3 the strongest open-weight option available today for building agentic systems that need reliable multi-step tool orchestration. 76.12% on BankerToolBench and 89.35% on SpreadSheetBench-v1 confirm structured data and tool-heavy workflows are a strong suit.
Research and data science teams: The paper reproduction chart tells a clear story: M3 maintained consistent progress across 12 hours, completing the full reproduce.sh pipeline and reaching a final score of 0.650 - above all competitors except GPT-5.5 (0.84, against a reference ceiling of 0.91). For teams that want an AI research assistant capable of running real experiments, not just summarizing papers, this matters.
Spreadsheets and office workflows: 89.35% on SpreadSheetBench-v1 and 45.1% on OfficeQA Pro (above Opus 4.7 at 43.6%) indicate M3 is well-suited for enterprise office automation at scale.
Why Qubrid AI for MiniMax M3 Access
Qubrid AI exists to eliminate the overhead between a new model launching and your team actually using it. The platform provides unified API access across leading open source & frontier models, so the cost of switching, experimenting, and comparing isn't borne by your engineering team - it's abstracted by the platform.
Being a Day 0 partner for MiniMax M3 means Qubrid users have immediate access to the model at the same moment it becomes available globally. No separate API approval, no new credentials setup, no fragmented infrastructure. You can run M3 alongside GPT-5.5, Gemini 3.1 Pro, or Claude Opus 4.7 within the same Qubrid environment, route traffic across models, and benchmark against your own production data using tooling you already have in place.
For teams evaluating M3 against other frontier models for a specific workload - which is exactly the evaluation you should be running before committing to a model in production - Qubrid's model comparison tooling makes that fast and systematic. The value isn't just access. It's the ability to make a well-informed decision quickly, without spinning up a new account for every model you want to test.
50% Off for Early Adopters
To mark the Day 0 launch, we are offering 50% off MiniMax M3 access for early adopters for a limited time.
At $0.30 per million input tokens and $1.20 per million output tokens - with cached input at just $0.06/M - MiniMax M3 on Qubrid AI is priced to make production deployment genuinely accessible. Factor in the limited-time 50% early adopter discount and the economics become hard to ignore for teams evaluating frontier-class models at scale.
If you have workloads - agentic pipelines, long-document processing, autonomous coding workflows, multimodal document intelligence, CUDA-level engineering tasks - that would benefit from what this model architecture delivers, now is the time to run the experiment.
Access MiniMax M3 on Qubrid AI: https://platform.qubrid.com/model/minimax-m3
The discount is limited. The model is ready today.
What M3 Signals About the Next Phase of Frontier AI
It would be easy to frame MiniMax M3 as a competitive catch-up story - another lab reaching for the performance level of OpenAI and Anthropic. That framing misses what's actually interesting here.
M3 demonstrates that open-weight models are no longer structurally limited to being second-tier alternatives to closed-source systems. The MSA architecture is a genuine innovation in attention mechanisms, not a scaling optimization. The agentic capability demonstrated in the CUDA and PostTrainBench evaluations reflects training methodology advances - the interactive user simulator framework, the interleaved multimodal training pipeline, the 100-trillion-token data scale - not just parameter count. The native multimodality reflects an architectural decision made at training inception, not an integration decision made afterward.
The broader signal is about what frontier AI development looks like when multiple capable labs are competing seriously across different architectural approaches. The labs winning right now aren't winning only by spending more on compute. They're winning by solving the right technical problems in ways that generalize. MSA is one example. The paper reproduction score trajectory is another - a 12-hour autonomous research run that meaningfully outpaced every competitor except GPT-5.5 is not a benchmark. It's a proof of concept for a new category of AI capability.
For developers and AI teams, this trajectory is good news: more capable open-weight models, better inference economics, arriving faster, and accessible through platforms that make the transition from experiment to production straightforward.
That is the environment MiniMax M3 launches into today. It's a strong model released at the right moment.
Try MiniMax M3 on Qubrid AI now - 50% off for early adopters: https://platform.qubrid.com/model/minimax-m3


