Qwen 3.7 Max vs Claude Opus 4.7: Can Alibaba Finally Challenge Anthropic's Coding King?
The race for the world's best AI model has become increasingly competitive. What was once a battle dominated by OpenAI and Anthropic now includes serious challengers from Qwen, and perhaps none is more ambitious than Alibaba's latest flagship model, Qwen 3.7 Max.
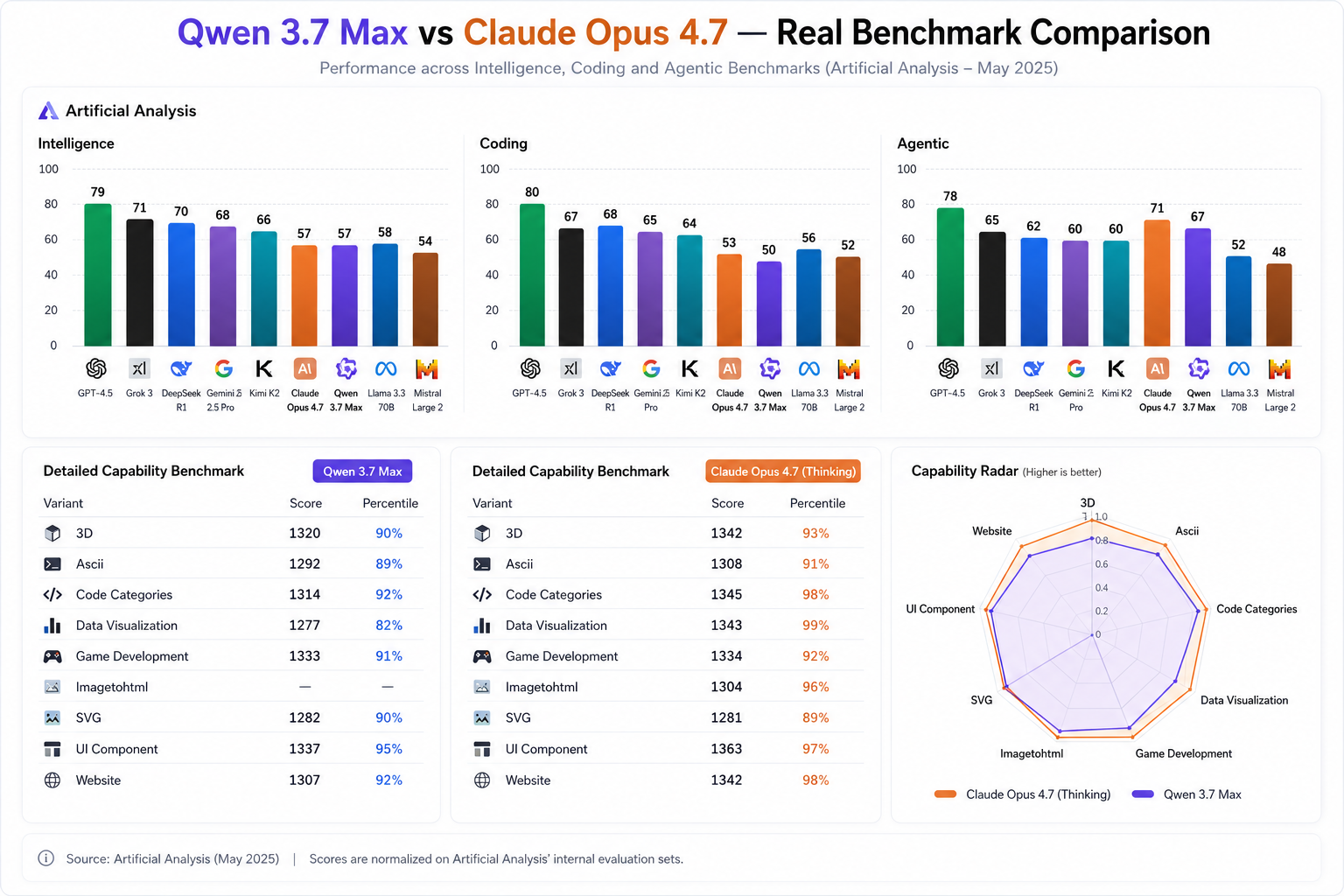
With Alibaba positioning Qwen 3.7 Max as an "agent-era" model built for autonomous execution, coding, and workflow automation, developers naturally want to know how it compares against one of the industry's strongest models: Claude Opus 4.7.
Claude Opus has built a reputation for exceptional software engineering capabilities, long-context reasoning, and enterprise reliability. It powers coding assistants, research workflows, and AI agents across thousands of organizations worldwide. But Qwen 3.7 Max arrives with a different proposition: deliver near-frontier intelligence while dramatically reducing inference costs.
The question isn't simply which model is better. The real question is whether Qwen has become good enough to replace Claude in production systems.
Let's find out.
Understanding the Two Models
Although both models target developers, they were designed with slightly different philosophies.

Anthropic built Claude Opus 4.7 to maximize reasoning quality, software engineering performance, and reliability. The model excels at understanding large codebases, debugging complex systems, and maintaining coherent reasoning over extremely long contexts.
Qwen 3.7 Max, on the other hand, was designed around a future where AI systems do more than answer questions. Alibaba's focus is clearly visible throughout the model's design. Rather than optimizing exclusively for benchmark scores, Qwen emphasizes autonomous execution, tool use, planning, and multi-step workflows.
In practice, this means Claude often behaves like a senior software engineer, while Qwen frequently feels like an autonomous operator capable of executing entire workflows with minimal intervention.
Coding Performance: The Most Important Test
For most developers, coding quality remains the single most important metric.
In day-to-day software engineering tasks, Claude Opus 4.7 consistently demonstrates why Anthropic continues to dominate coding benchmarks. The model produces highly structured code, understands architectural tradeoffs, and frequently catches subtle implementation issues before they reach production.
When asked to refactor large codebases, design distributed systems, or debug complex backend services, Claude often provides explanations that resemble the thought process of experienced engineers.
Qwen 3.7 Max performs remarkably well in coding tasks too. It generates clean code, handles modern frameworks competently, and performs strongly in repository-level tasks. The gap between Qwen and Claude is significantly smaller than many developers might expect.
However, the difference becomes apparent as task complexity increases. On larger software engineering problems involving architecture decisions, dependency management, and debugging chains, Claude generally produces more reliable outputs.
For pure coding quality, Claude still maintains the lead.
Where Qwen Starts Fighting Back
The story becomes much more interesting once workflows extend beyond code generation.
Modern AI applications increasingly rely on agents that must plan actions, call tools, retrieve information, update databases, and continue operating across dozens or even hundreds of steps.
This is precisely where Qwen 3.7 Max shines.
During agent-style workflows, Qwen demonstrates impressive persistence. It tends to maintain momentum across long execution chains and often requires fewer corrections when coordinating multiple tools. Tasks such as browser automation, research workflows, document processing, and customer support automation align closely with the model's strengths.
Rather than simply generating answers, Qwen appears optimized for completing objectives.
Claude remains excellent at tool use, but Qwen's agent-centric design gives it a noticeable advantage in autonomous workflow execution.
For teams building AI agents, this distinction matters more than benchmark scores.
Long Context and Knowledge Retention
As organizations increasingly work with large repositories, documentation libraries, and research datasets, context length has become a major competitive battleground.
Claude Opus 4.7 continues to set the standard for long-context reasoning. Whether analyzing thousands of lines of source code or reviewing extensive documentation, the model demonstrates impressive consistency in retrieving and connecting information from distant parts of a context window.
Developers working with enterprise knowledge bases often report that Claude maintains coherence even when operating on extremely large inputs.
Qwen 3.7 Max handles long contexts effectively as well, but its primary advantage lies elsewhere. While Claude focuses on extracting and reasoning over information, Qwen's strength emerges once it begins acting on that information through planning and execution.
The result is a subtle but important distinction.
Claude is generally better at understanding large contexts.
Qwen is often better at doing something useful with them.
The Economics of AI at Scale
Capability alone doesn't determine adoption.
For many organizations, cost has become just as important as benchmark performance.
This is where Qwen 3.7 Max becomes difficult to ignore.
Even a small reduction in token costs can translate into hundreds of thousands of dollars in annual savings for high-volume AI applications. For startups building AI-native products, lower inference costs can dramatically improve margins without sacrificing much capability.
Claude Opus 4.7 remains a premium model and commands premium pricing. The cost is often justified by its superior reasoning and engineering performance, but not every application requires the absolute best model available.
Many organizations would gladly accept 95% of Claude's capability for a significantly lower operating cost.
Qwen is increasingly becoming that alternative.
Real-World Developer Experience
Perhaps the most interesting takeaway from testing both models is how differently they feel.
Claude often behaves like an experienced engineer sitting beside you. It explains decisions clearly, identifies risks, and demonstrates exceptional judgment when navigating complex technical problems.
Qwen behaves more like an eager operator focused on completing the task.
If your workflow involves reviewing architecture decisions, conducting code audits, or solving difficult engineering challenges, Claude feels superior.
If your workflow involves orchestrating tools, automating repetitive tasks, or building autonomous systems, Qwen often feels faster and more practical.
Neither approach is inherently better.
The ideal choice depends entirely on the problem you're trying to solve.
The Verdict
A year ago, comparing Qwen models directly against Anthropic's flagship would have felt ambitious.
Today, it feels entirely justified.
Claude Opus 4.7 remains the stronger model overall. It delivers better reasoning, superior software engineering performance, stronger long-context understanding, and the reliability enterprises expect from a frontier AI system.
Yet Qwen 3.7 Max achieves something arguably more important.
It closes the gap.
For teams building AI agents, workflow automation systems, and cost-sensitive applications, Qwen 3.7 Max offers a combination of capability and efficiency that is difficult to ignore.
If you need the absolute best model available, choose Claude Opus 4.7.
If you need the best balance between performance, scalability, and cost, Qwen 3.7 Max may be one of the most compelling models available today.
And perhaps for the first time, Anthropic has a challenger that deserves to be taken seriously.
Try Qwen 3.7 Max on Qubrid AI

Qwen 3.7 Max is available through Qubrid AI alongside leading models from Anthropic, DeepSeek, Kimi, GLM, MiniMax, OpenAI, and more - all through a single unified API and developer playground.


